MySQL InnoDB 锁的类型
InnoDB 中的锁,可以分为表锁、意向锁、行锁和自增 ID 锁。这些锁都是内存中的结构,可以在 performance_schema 库中的 data_locks 表和 data_lock_waits 表中查看当前系统中有哪些锁,以及锁等待关系。

查询锁的情况
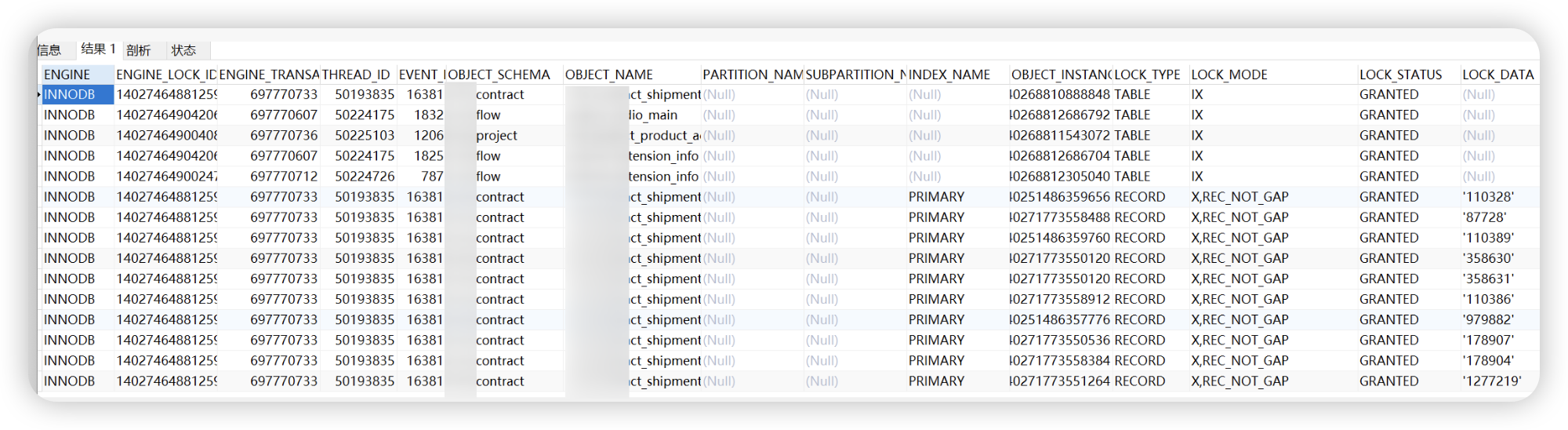
data_locks 表用于查看有哪些锁
| 字段 | 说明 |
|---|---|
| ENGINE | 存储引擎,一般为 InnoDB |
| ENGINE_LOCK_ID | 锁 ID |
| ENGINE_TRANSACTION_ID | 请求锁的事务 ID |
| THREAD_ID | 请求锁的线程 ID。thread_id 可以和 threads 表关联。注意,这里的 thread_id 和 information_schema.processlist 表的 ID 不一样。关联 threads 表后可以获取 PROCESSLIST_ID 字段 |
| EVENT_ID | 事件 ID |
| OBJECT_SCHEMA | 表所在的 schema |
| OBJECT_NAME | 表名 |
| PARTITION_NAME | 分区名。对非分区表,该字段为 null |
| SUBPARTITION_NAME | 子分区名。对非分区表,该字段为 null |
| INDEX_NAME | 索引名 |
| OBJECT_INSTANCE_BEGIN | 锁的内存地址 |
| LOCK_TYPE | 锁的类型 RECORD:记录锁 TABLE:表锁 |
| LOCK_MODE | 锁的模式: S:共享锁 X:排他锁 IS:意向共享锁 IX:意向排他锁 GAP:间隙锁,锁的是索引记录与前一条记录之间的区间 REC_NOT_GAP:记录锁。只锁索引记录,不锁记录前的区间 INSERT_INTENTION:插入意向锁 AUTO_INC:自增长 ID 锁 |
| LOCK_STATUS | 锁请求的状态 GRANTED:已经获取到锁 WAITING:等待中 |
| LOCK_DATA | 对于 InnoDB 的记录锁: - 如果是主键上的锁,lock_data 显示为主键字段的值。 - 如果是二级索引上的锁,lock_data 显示为二级索引列的值和主键值。 - 如果 lock_data 显示为 supremum pseudo-record,则说明锁的记录是虚拟的 supremum 记录。 |
data_lock_waits 表用于查看锁等待关系
| 字段 | 说明 |
|---|---|
| ENGINE | 存储引擎,一般为 InnoDB |
| REQUESTING_ENGINE_LOCK_ID | 等待锁的事务的锁 ID |
| REQUESTING_ENGINE_TRANSACTION_ID | 等待锁的事务 ID |
| REQUESTING_THREAD_ID | 等待锁的线程的 ID。可以和 threads 表关联,获取线程的更多信息 |
| REQUESTING_EVENT_ID | 等待锁的事件 ID |
| REQUESTING_OBJECT_INSTANCE_BEGIN | 等待的锁在内存中的地址 |
| BLOCKING_ENGINE_LOCK_ID | 阻塞锁的事务的锁 ID |
| BLOCKING_ENGINE_TRANSACTION_ID | 阻塞锁的事务 ID |
| BLOCKING_THREAD_ID | 阻塞线程的 ID。可以和 threads 表关联,获取线程的更多信息 |
| BLOCKING_EVENT_ID | 阻塞锁的事件 ID |
| BLOCKING_OBJECT_INSTANCE_BEGIN | 阻塞锁在内存中的地址 |
Innodb 锁的分类
表锁
想给表上锁,用的是 lock tables 这条命令。
但是有个坑你得注意:只有在关了自动提交(也就是先执行 set autocommit=0)的情况下,再去执行 lock tables,才能真正拿到 InnoDB 层意义上的表锁。不然可能是假的,或者锁不住。
另外,如果你想看锁的日志,可以去 data_locks 这张表里瞅一眼。表锁在那里面,LOCK_TYPE 那一列写的是 TABLE,LOCK_MODE 要么是 X(写锁)要么是 S(读锁)。
set autocommit=0;
lock table emp read, tb_user write;
select engine, object_schema, object_name, lock_type, lock_mode from `performance_schema`.data_locks;

select object_type, object_name, lock_type, lock_status from `performance_schema`.metadata_locks ORDER BY object_name;
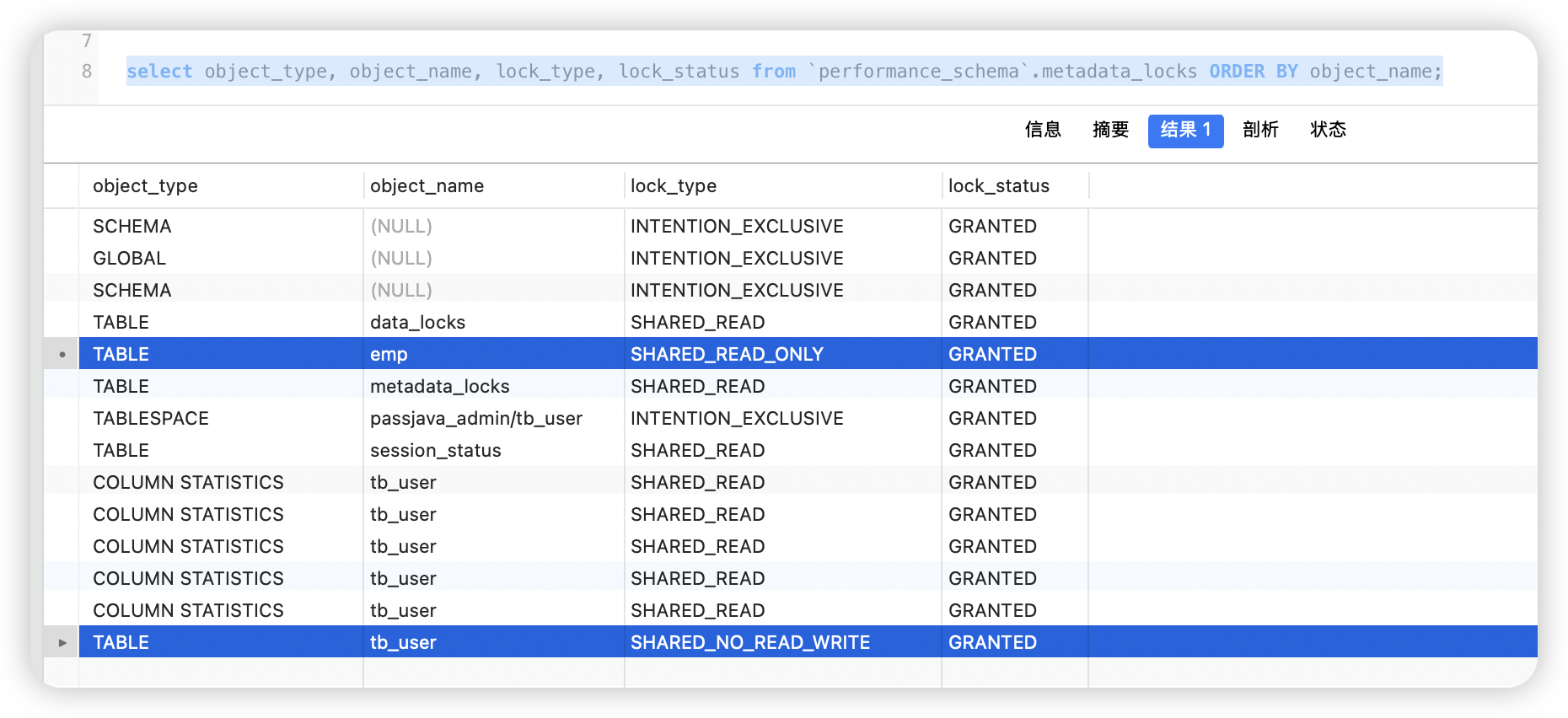
给一张表加上读锁之后,谁拿到这个锁,就只能查数据,不能改。你要是硬改,就会报错说“这张表被读锁锁住了,更新不了”。其他会话(也就是别的连接)同样也只能查,不能改。
如果换成写锁,那就更狠了——别的会话连查都查不了,更别说改了。
其实在正经的业务系统里,表锁用得不多。
踩坑
用 mysqldump 备份数据的时候,如果你不加 --skip-lock-tables 或者 --single-transaction 这两个参数,它默认就会给表加锁(读锁),备份期间可能会影响业务正常读写。
意向锁
InnoDB 在给某条具体的记录加锁之前,得先拿到表级别的“意向锁”——相当于提前打个招呼:“我要在这一行上搞事情了”。
如果你要加的是写锁(X 锁),那意向锁就是 IX(意向写锁);如果加的是读锁(S 锁),意向锁就是 IS(意向读锁)。
在 data_locks 表里看的话,意向锁的 lock_type 也是 TABLE,只不过 lock_mode 是 IS 或 IX,不是普通的表锁的 S 或 X。
begin;
select * from emp for share;
select * from tb_user for update;
select object_schema, object_name, lock_type, lock_mode, lock_data from `performance_schema`.data_locks order by lock_mode, object_name;
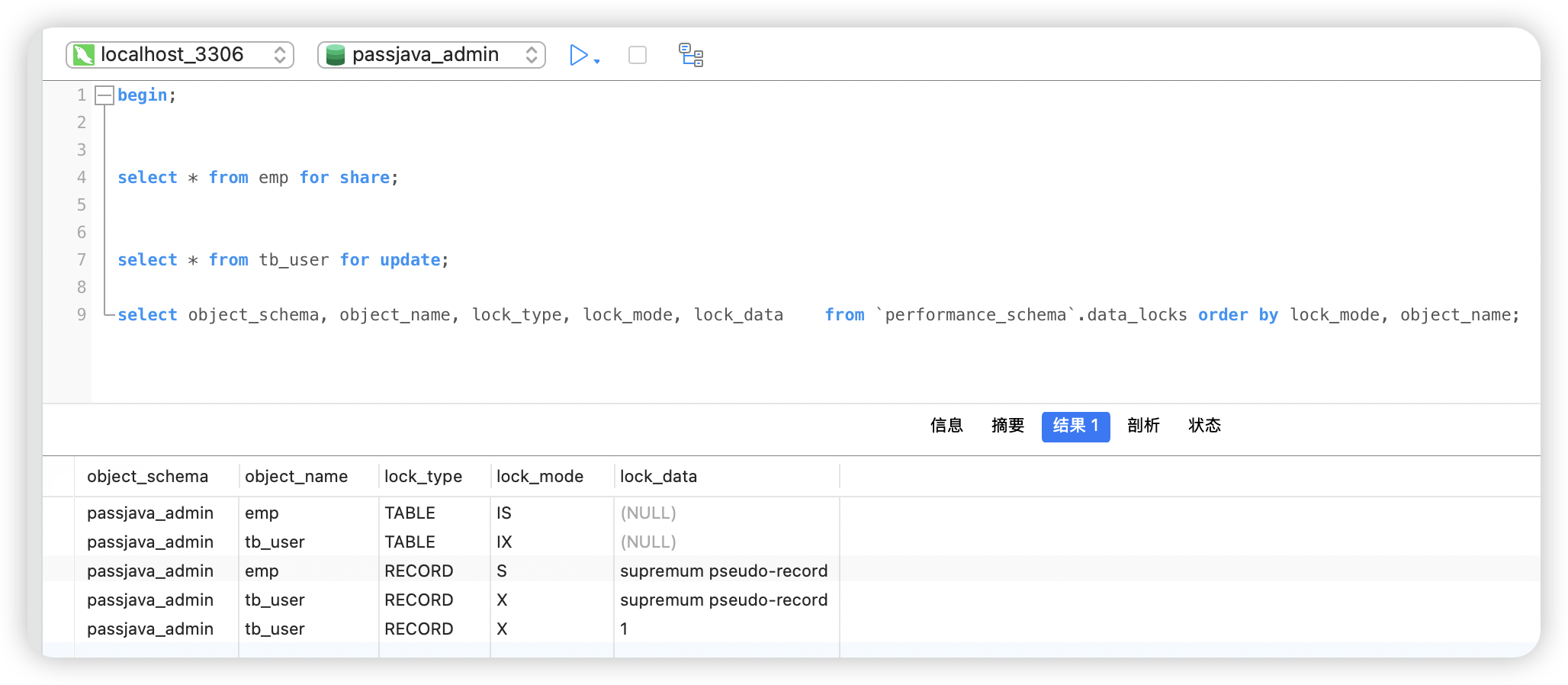
为什么要用意向锁?说白了就是为了“省事”。
你想啊,如果没有意向锁,万一有个事务想给整个表加写锁(比如 LOCK TABLES t WRITE),那它就得把表里所有的记录都扫一遍,看看有没有哪一行被别的事务锁着。这得多费劲?表大了不得扫半天?
有了意向锁就不一样了:
- 每个要加行锁的事务,先给表打个“小报告”——加一个意向锁(IS 或 IX),就相当于喊一声:“我要在这表里的某几行上干活了,读写都有”。
- 后来想给整个表加锁的人一看表上有没有意向锁,就知道有没有人在动行数据。有 IX 或 IS?那说明有人在行级别上占着坑呢,我整个表锁就拿不到,直接拒绝或者等,不用去翻每一行了。
意向锁就是个“状态标签”,让你不用挨个扒拉行记录,看一眼表就知道干不干得了。
记录锁(行锁)
MySQL 平时跑普通的 select 查询,是不给记录上锁的。
只有当你执行 insert、update、delete,或者用了 select ... for share、select ... for update 这种语句的时候,它才会正儿八经地给你加锁。
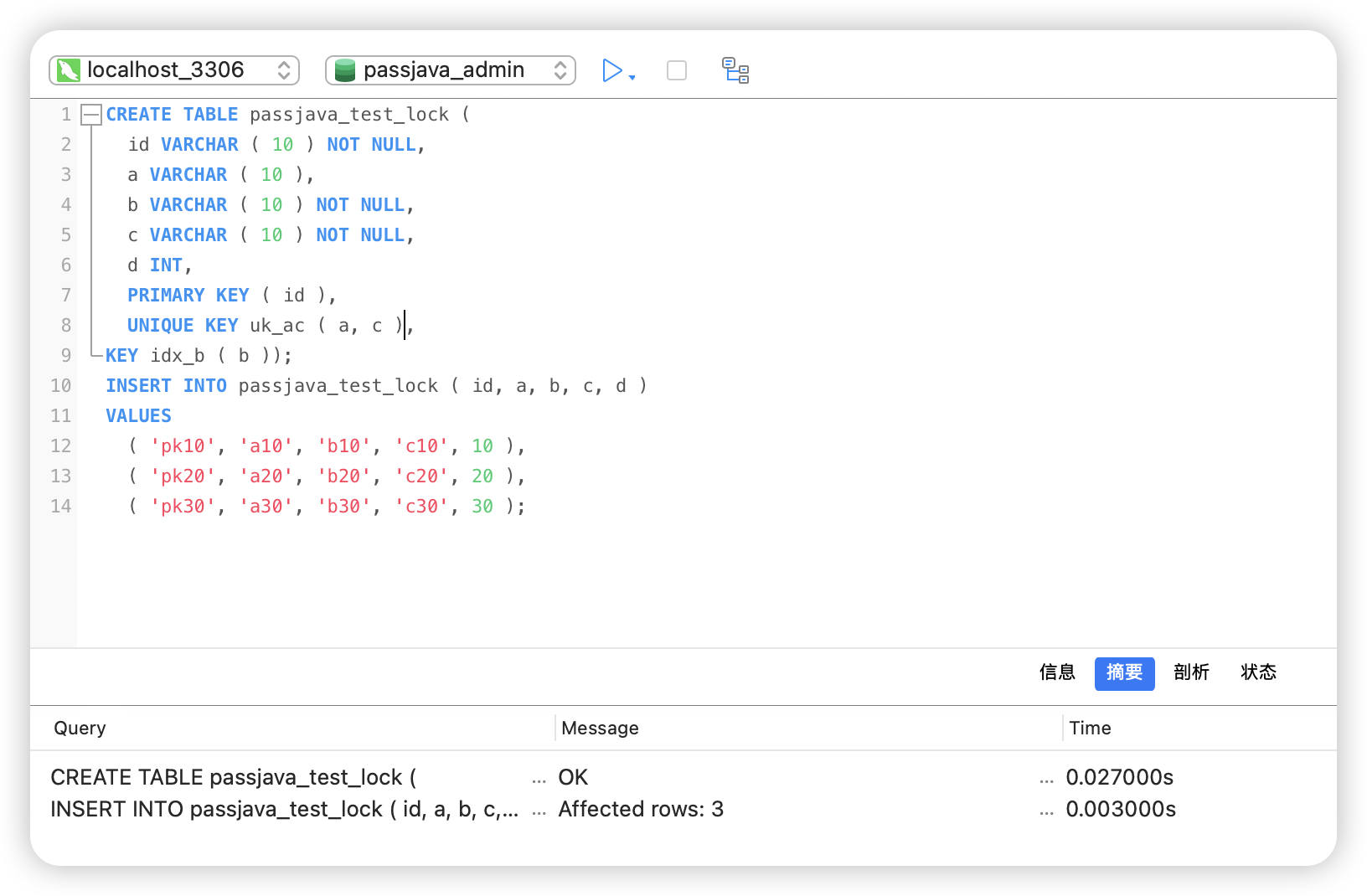
创建测试数据
CREATE TABLE passjava_test_lock (
id VARCHAR ( 10 ) NOT NULL,
a VARCHAR ( 10 ),
b VARCHAR ( 10 ) NOT NULL,
c VARCHAR ( 10 ) NOT NULL,
d INT,
PRIMARY KEY ( id ),
UNIQUE KEY uk_ac ( a, c ),
KEY idx_b ( b ));
INSERT INTO passjava_test_lock ( id, a, b, c, d )
VALUES
( 'pk10', 'a10', 'b10', 'c10', 10 ),
( 'pk20', 'a20', 'b20', 'c20', 20 ),
( 'pk30', 'a30', 'b30', 'c30', 30 );
记录锁
当你的事务隔离级别是 READ COMMITTED,或者你用的是唯一索引(比如主键)做等值查询时,InnoDB 只会锁住那一条记录,不会锁它前面的“间隙”——也就是不会阻止别的事务在它前后插新数据。
这种只锁记录、不锁间隙的锁,在 data_locks 表里,lock_type 是 RECORD,lock_mode 会写成 X,REC_NOT_GAP(写锁)或者 S,REC_NOT_GAP(读锁)。看到 NOT_GAP 就说明:“我锁的是记录本身,不关间隙的事。”
读已提交(READ COMMITTED)
在这个隔离级别下,InnoDB 只锁记录本身,不锁记录之间的间隙(GAP)。
set autocommit=0;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
select * from passjava_test_lock where b='b20' for update;
select object_name, index_name, lock_type, lock_mode, lock_data from `performance_schema`.data_locks order by object_name;
commit
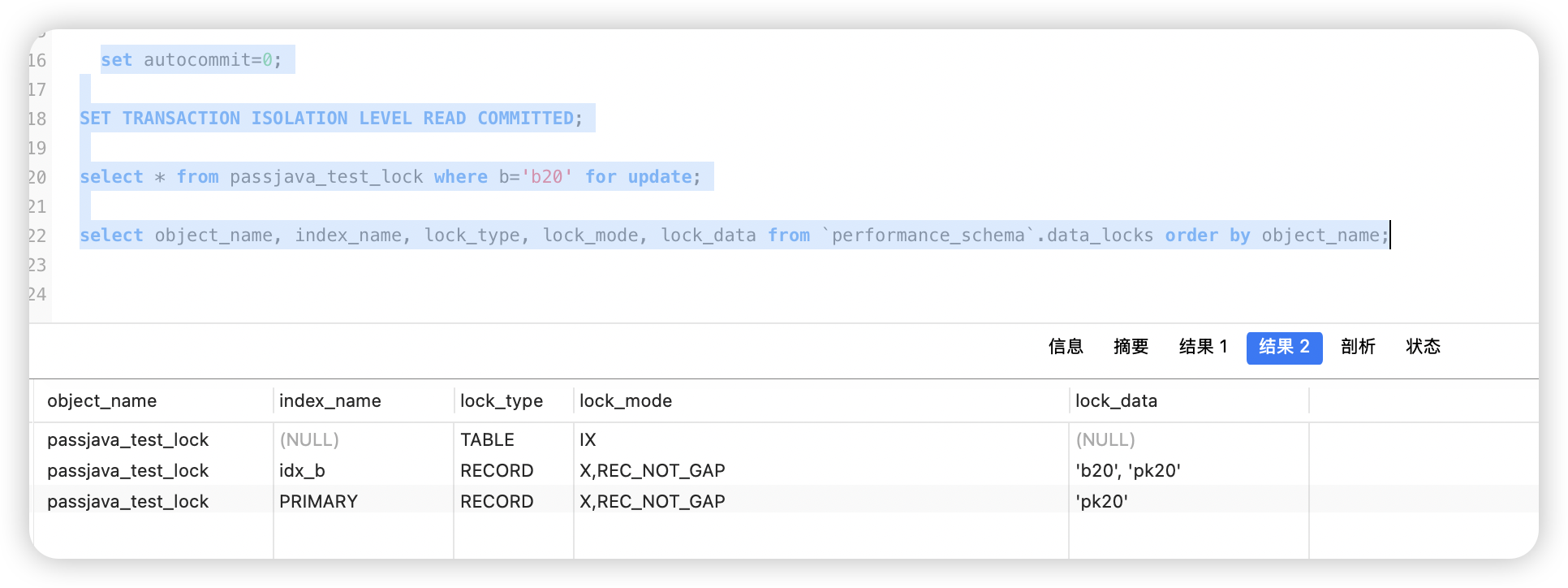
上面这个例子中,使用了索引 idx_b,获取了索引 idx_b 上记录(b20, pk20)和主键 pk20 的记录锁,注意 lock_mode 中有 REC_NOT_GAP。
可重复读(REPEATABLE READ) + 唯一索引等值查询(命中)
set transaction isolation level repeatable read;
begin;
select * from passjava_test_lock where a='a20' and c='c20' for update;
select object_name, index_name, lock_type, lock_mode, lock_data from `performance_schema`.data_locks order by object_name;
commit
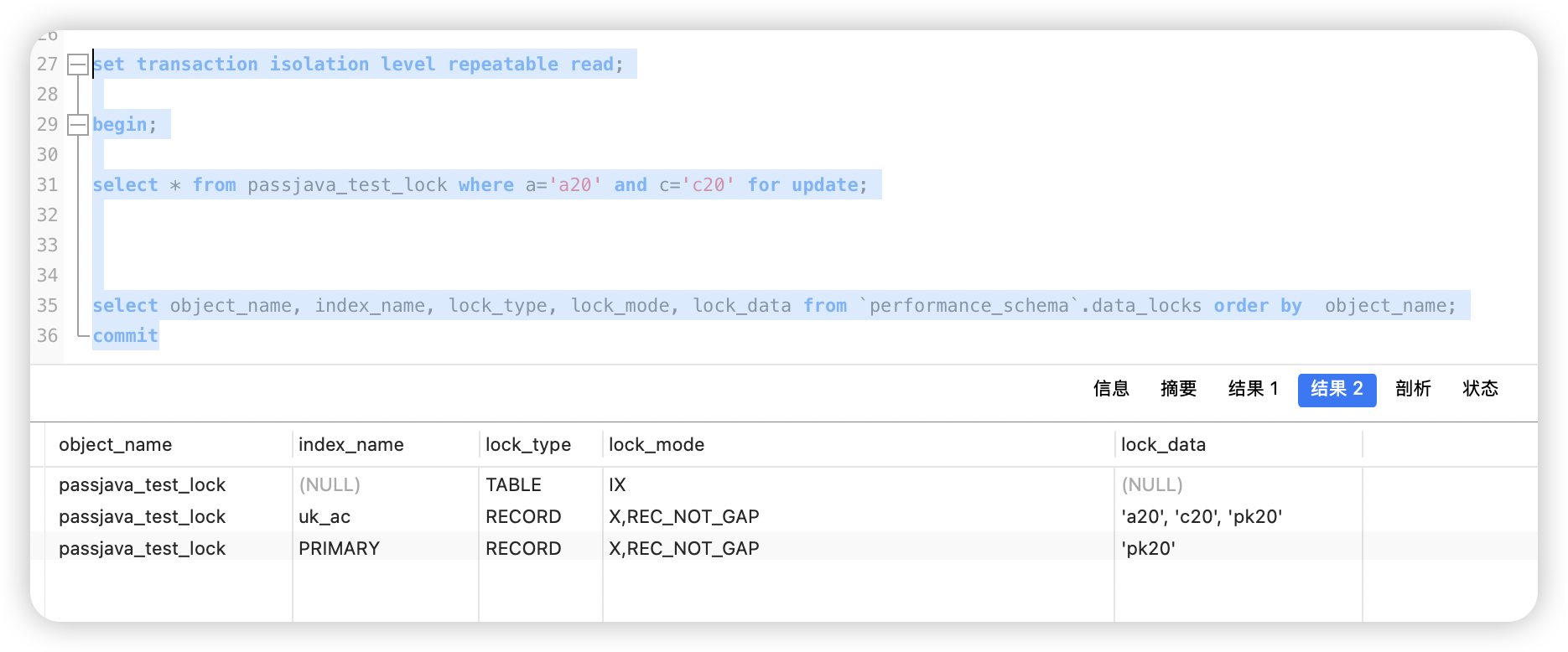
上面这个例子中,使用唯一索引 uk_ac 访问,获取了 uk_ac 上记录(a20,c20,pk20)和主键 pk20 上的锁,lock_mode 有 REC_NOT_GAP。
这时候 InnoDB 也只锁那一条记录,不锁间隙 —— 还是 REC_NOT_GAP。
因为唯一索引能精准定位,锁多了没用,而且也不会产生幻读。
可重复读 + 唯一索引等值查询(没命中)
repeatable read 隔离级别下,如果使用唯一索引没有匹配到相关记录。或者唯一索引为组合索引的情况下,没有匹配所有的索引字段,则还需要锁定记录前的 GAP。
set transaction isolation level repeatable read;
begin;
select * from passjava_test_lock where a='a15' and c='c15' for update;
select object_name, index_name, lock_type, lock_mode, lock_data from `performance_schema`.data_locks order by object_name;
commit
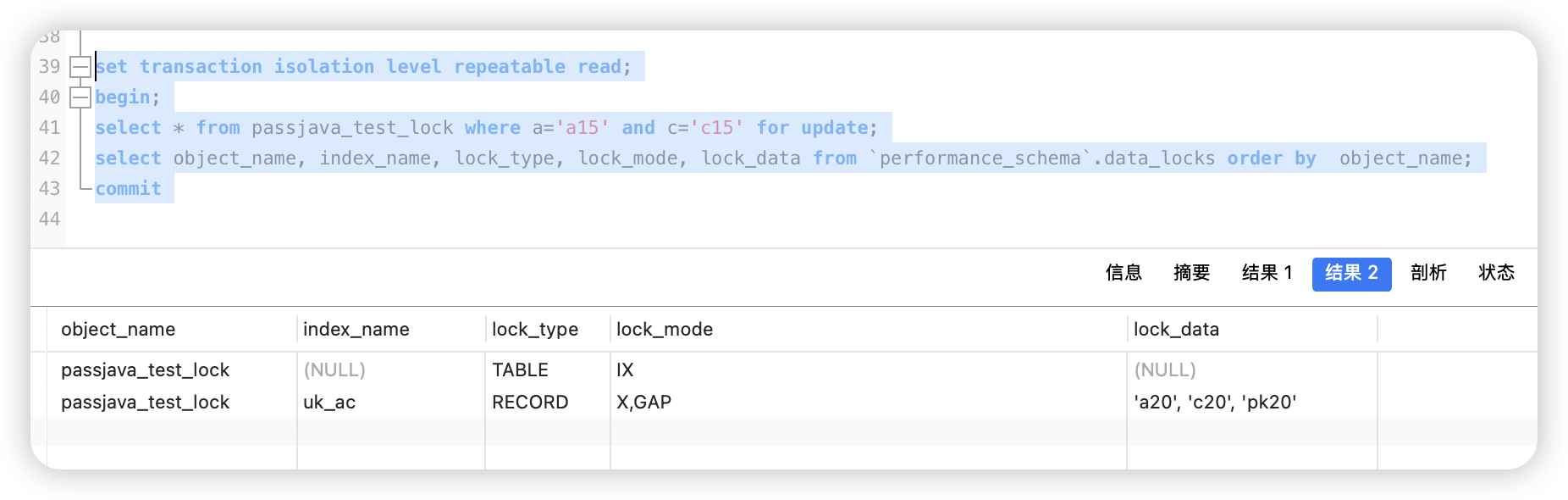
你查 a='a15' and c='c15',但表里根本不存在这条记录。
这时候 InnoDB 虽然没锁到具体记录,但为了防止幻读,它会把这条记录“理论上该在的位置”前面的间隙给锁住。
从 data_locks 看,lock_mode 是 X,GAP,锁的数据是下一个真实记录(比如 ('a20','c20'))之前的那个空隙。
意思是:这个区间里,别的事务别想插 ('a15','c15') 这样的数据进来。
- RC 隔离:只锁记录,不锁间隙。
- RR + 唯一索引命中:也是只锁记录,不锁间隙。
- RR + 唯一索引没命中(或组合索引没用全):锁间隙(GAP),防止幻读。
可重复读(RR) + 唯一索引但只用了一部分条件(前缀)'
你有一个唯一索引 uk_ac 是 (a, c) 两个字段。但你查询只用了 a = 'a20',没给 c 的值。
这就好比你去图书馆找书,明明索引牌上写着“书架号 + 层号”,你却只报了“书架号”,没报“层号”。
图书馆管理员(InnoDB)说:“抱歉,我没办法精确定位到具体某一本书,只能把那一整层可能的位置都盯住,防止别人乱放书。”
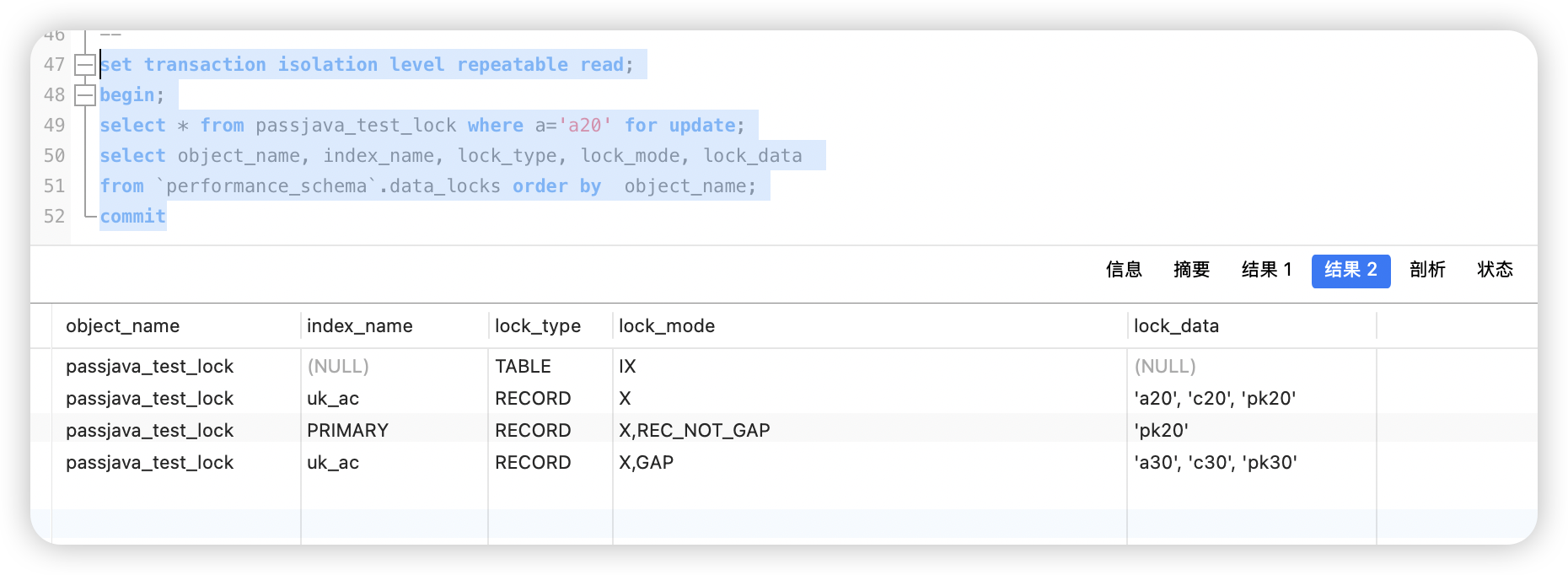
具体表现在锁上:
- 表上加了一个意向写锁(
IX),正常。 - 主键上给匹配到的
pk20加了记录锁(X,REC_NOT_GAP),因为确实找到了一条a='a20'的记录。 - 在唯一索引
uk_ac上:- 先锁住了实际匹配的那条
('a20', 'c20', 'pk20')的记录,锁模式是X(这里其实相当于 next-key 锁,但没有显示GAP是因为它锁了自己和前面的间隙,但你看到的是 X 默认就是 next-key)。 - 然后又额外锁了下一个记录
('a30', 'c30', 'pk30')前面的间隙,锁模式是X,GAP。
- 先锁住了实际匹配的那条
为什么会有 X,GAP 在下一个记录上?
因为 InnoDB 担心:虽然你现在查到一条 a='a20' 的记录,但万一有别人在这个值附近插入新的 a='a20' 但 c 不同的记录,就会造成幻读。
所以它把 a='a20' 这个值的范围(从当前记录到下一个不同的 a 值之前的间隙)都给锁了。下一个记录的 a='a30',所以从 ('a20','c20') 到 ('a30','c30') 之间的空隙不能插新数据。
GAP 锁
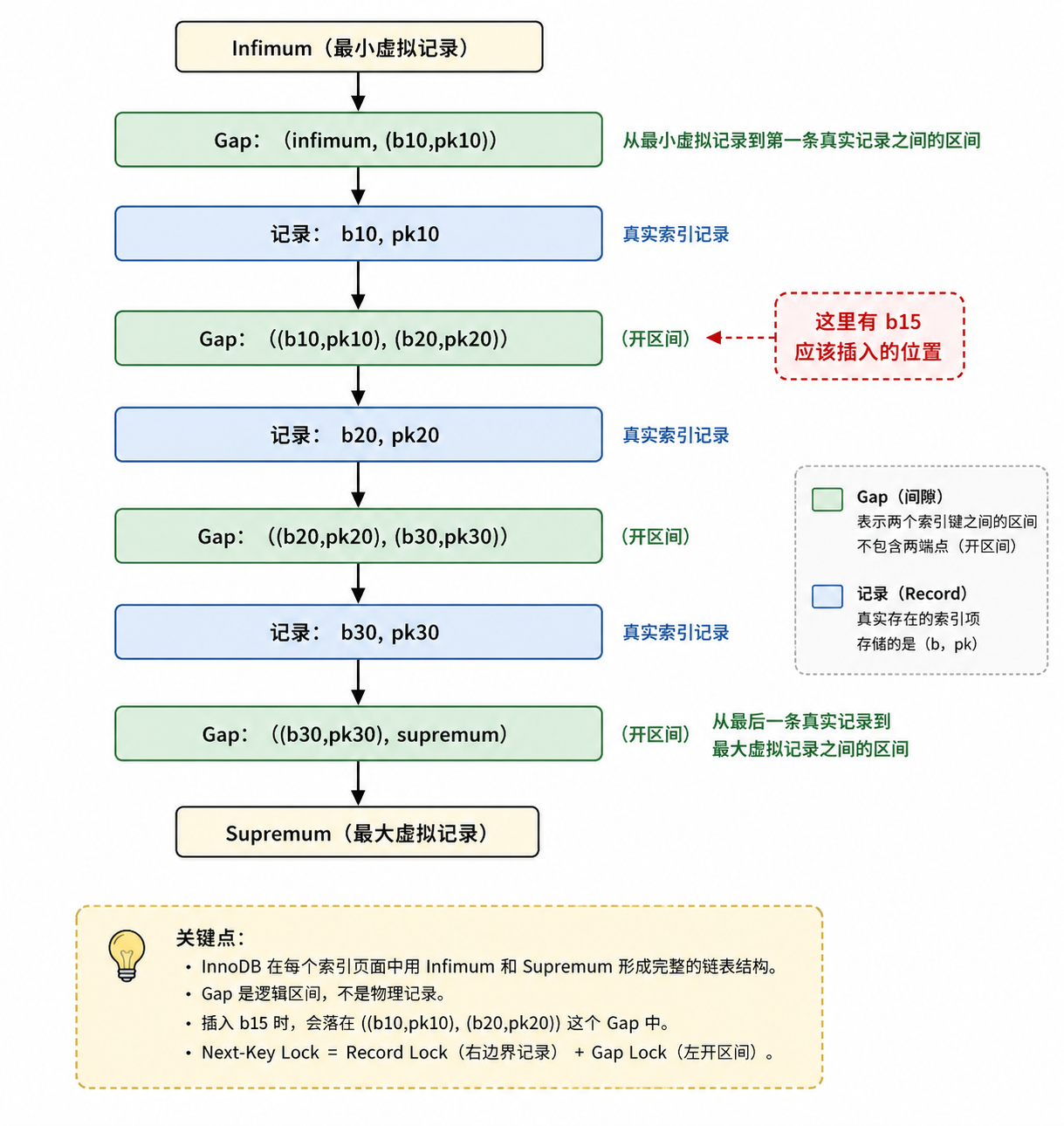
GAP 锁其实就是用来锁住两个索引记录之间的“空隙”的。
在 data_locks 表里,它的 lock_mode 会写成 X,GAP(写间隙)或者 S,GAP(读间隙),lock_data 显示的是这个区间的右边界。
为啥要有这玩意儿呢?主要是为了在 REPEATABLE READ(可重复读)或更高隔离级别下,防止出现“幻读”——就是同一个查询在事务中间突然多出几行来。GAP 锁的作用就是:这块区间我罩着了,别的事务别想往里插新数据。
从实现上讲,GAP 锁并不是一个独立的东西,它实际上是挂在索引的叶子节点(记录)上的。
再看一个 GAP 锁的真实例子。
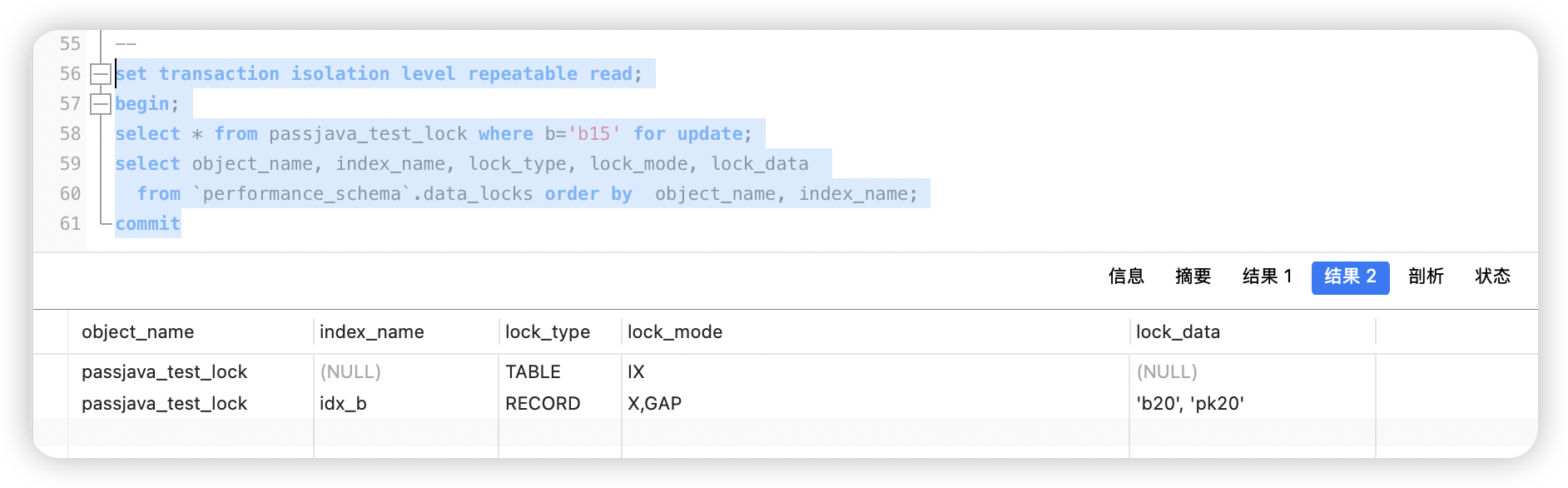
你执行 select * from test_lock where b='b15' for update,但是表里压根儿没有 b='b15' 这条记录。
可别以为没记录就不加锁了——在可重复读(RR)隔离级别下,InnoDB 照样会给你上一个 GAP 锁。
从 data_locks 表里能看到,锁类型是 X,GAP,锁的数据是 'b20', 'pk20'。
这啥意思呢?
因为索引 idx_b 是按 B+ 树排好序的,b='b15' 这条记录理论上应该插在 b='b10' 和 b='b20' 之间。
所以 InnoDB 就把这个区间 (b10, b20) 给锁住了——不是锁某一条记录,而是锁住这个“空隙”。
这么一锁,别的事务就别想在这个区间里插入 b='b15' 的新数据,也别想把某条记录的 b 字段改成 b10 到 b20 之间的值。
这样一来,你再通过 b='b15' 查询,永远都是空,不会突然冒出个新记录——幻读就被防住了。
问题:为啥 lock_data 显示的是 'b20', 'pk20',而不是 (b10, b20)?
🐒空哥提示:因为 GAP 锁虽然锁的是“两个记录之间的空隙”,但 MySQL 在记录锁信息的时候,得找个实实在在的对象来“代表”这个空隙。
它选的就是这个空隙右边的那条记录(也就是下一个真实存在的记录)。在你这个例子里:
- 你查
b='b15',不存在- 按 B+ 树顺序,它应该插在
b='b10'和b='b20'之间- 这个空隙的右边就是
b='b20'那条记录- 所以
lock_data就记成'b20', 'pk20',表示:“我锁的是'b20'这条记录前面的那个间隙”换句话说,
lock_data不是告诉你“锁了哪段区间”,而是告诉你“这条记录前面的空隙被锁了”。
如果你看到lock_mode里有GAP,那lock_data指的就是那个空隙的右边界记录。
问题:但是会不会锁多了呢,比如 b20 之前的记录,其实也包含 b10 之前的数据?
🐒空哥提示:**不会锁多,GAP 锁的范围就是
(b10, b20)这个开区间,不包含b10本身,更不包含b10之前的数据。**InnoDB 的 GAP 锁是“夹在两个相邻索引记录之间的空隙”。GAP 锁用右边界标记,只锁它和左边邻居之间的空隙,不越界。
Next-Key 锁
Next-key 锁其实就是 记录锁 + GAP 锁 的合体。
它既锁住那条记录本身,也锁住它前面的那个“间隙”。
在 data_locks 表里,它的 lock_type 还是 RECORD,lock_mode 就直接写 X 或 S,不会额外带 GAP 或 REC_NOT_GAP,但你别看它没写,它俩事儿都干了。
这个锁也是用在 可重复读(REPEATABLE READ) 隔离级别下,目的还是防幻读——不光挡住别人改现有行,连在前面空隙里插新行都不行。
下面有个 Next-Key 锁的示例。
set transaction isolation level repeatable read;
begin;
select * from passjava_test_lock where b = 'b20' for update;
select object_name, index_name, lock_type, lock_mode, lock_data
from `performance_schema`.data_locks order by object_name, index_name;
commit
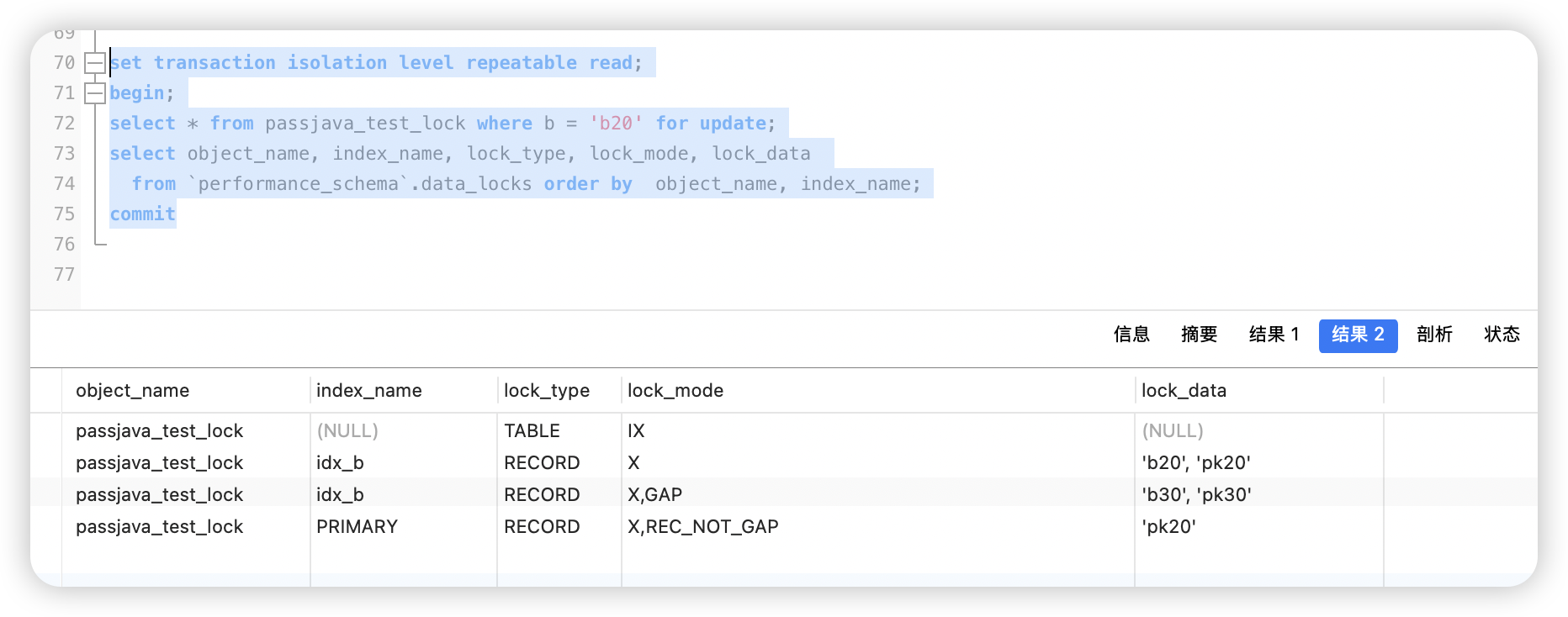
你执行 select * from test_lock where b='b20' for update,查出来了一条记录 (b20, pk20)。
在可重复读(RR)隔离级别下,InnoDB 为了防止幻读,不光要锁住 b20 这条记录本身,还要锁住它前面的空隙。
所以你会在 data_locks 里看到:
- 索引
idx_b上有一条记录,lock_mode是X,lock_data是'b20', 'pk20'
→ 这就是 Next-key 锁,它其实干了“锁记录 + 锁前面空隙”两件事,但在表里只显示成X(因为X默认就代表 next-key 锁)。 - 同一条索引
idx_b上还有另一条锁,lock_mode是X,GAP,lock_data是'b30', 'pk30'
→ 为啥会锁到b30前面?因为b20不是最后一个值,它后面还有b30。InnoDB 为了锁住b20到b30之间的空隙,就用了b30这条记录作右边界,加一个纯 GAP 锁。
→ 这样,别的事务想在(b20, b30)之间插数据(比如b25),就会被拦住。 - 主键上还有一条锁,
lock_mode是X,REC_NOT_GAP,lock_data是'pk20'
→ 这是单纯的记录锁,只锁主键那一行,跟间隙没关系。
总结这个例子:
b20这条记录上:Next-key 锁(锁自己 + 锁它前面的空隙,也就是(b10, b20])b30这条记录上:纯 GAP 锁(锁b20到b30之间的空隙,开区间)- 主键
pk20上:普通记录锁(只锁那一行)
所以 InnoDB 为了防止你下次再查 b='b20' 时出现幻读,不光把当前记录和它前面的空隙锁了,连它到下
一个记录之间的空隙也锁了。
这就是为啥你看到两条 idx_b 的锁,一条 X,一条 X,GAP。
🐒空哥提示:InnoDB 是通过“锁类型约定”来表达锁的哪些:
- 如果锁类型是
X,GAP→ 前面的空隙被锁了- 如果锁类型是
X,REC_NOT_GAP→ 自己这条记录被锁了- 如果锁类型是
X(无后缀)→ 两者都锁了,也就是(b10, b20]
插入意向锁
插入意向锁是干嘛的呢?就是当你打算往表里插一条新数据的时候,得先拿到这个“插入意向锁”——相当于
先跟你打算插进去的那个区间说一声:“嘿,我要往这儿插条数据了,让个道。”
InnoDB 防幻读,其实靠的就是 间隙锁(GAP 锁) 和 插入意向锁 哥俩配合:间隙锁说“这儿不许插”,插入
意向锁说“我就想插进来,等没锁了再插”。
所以它俩合起来,一个拦住别人乱插,一个等机会自己插,幻读就没了。
自增 ID 锁
自增 ID 锁(auto-inc 锁)自增 ID 锁是 InnoDB 中的一种特殊的锁,如果插入数据时用到了自增 ID,则需要先获取自增 ID 锁。获取自增 ID 锁的方式受参数 innodb_autoinc_lock_mode 控制。
InnoDB 锁兼容模式
锁兼容模式决定了多个会话是否能同时持有某个资源的锁。
| X | IX | S | IS | |
|---|---|---|---|---|
| X | Conflict | Conflict | Conflict | Conflict |
| IX | Conflict | Compatible | Conflict | Compatible |
| S | Conflict | Conflict | Compatible | Compatible |
| IS | Conflict | Compatible | Compatible | Compatible |
锁兼容性,说白了就是:多个连接能不能同时占着同一个资源不打架。
在 InnoDB 里:
- 表锁抢的是整张表;
- 记录锁(包括 GAP 锁、Next-key 锁)抢的是索引里的某条记录或者空隙。
1、表级别的意向锁(IX、IS)
- IX 和 IS 互相兼容,可以一起存在。
- 意向锁跟记录锁也不冲突,能和平共处。
2、表级别的排他锁(X)
- 这玩意儿最霸道,跟谁都不兼容。
- 只要有人锁了整张表的 X 锁,别人就别想再给这张表加任何锁(不管是 S 还是 X)。
3、表级别的共享锁(S)
- 只跟共享锁(S)兼容,排他锁(X)来了就滚蛋。
- 如果有人加了 S 锁,别人就加不了 X 锁。
4、GAP 锁(间隙锁)
- GAP 锁之间完全兼容,不管你是共享(S)还是排他(X)模式的 GAP,都可以一起存在。
- 为啥?因为 GAP 锁只干一件事:拦住别人往这个空隙里插数据。多个连接同时拦着同一个空隙,没问题,不打架。
5、Next-key 锁
- 它是 GAP 锁 + 记录锁的组合。
- 它的 GAP 部分,跟上面第四点一样,GAP 之间互相兼容。
- 它的记录锁部分,跟下面第六点一样,遵循记录锁的规则。
6、记录锁(锁具体某一行)
- 多个连接可以同时持有同一行的共享锁(S),大家都能读。
- 但是只要有一个人持有了这一行的排他锁(X),别人就别想再拿到这一行的共享锁或排他锁。