100多G数据同步引发的MySQL集群“连环炸”,我是如何一步步恢复的?

你好,我是悟空~又跟大家见面了~
背景
你好,我是悟空~又和大家见面了!
五一上线期间,我们迎来了一场不小的挑战:新系统需要将旧系统(SQL Server)中 100 多 G 的历史数据同步过来,同步方式采用了 DataX 工具 与 Java 程序 双管齐下。就在这个过程中,MySQL 集群接连抛出多个棘手问题,差点让上线计划卡壳。
下面我会把遇到的问题、当时的应急方案、最终解决方案以及效果,逐一梳理出来,希望能给遇到类似场景的朋友一些参考。
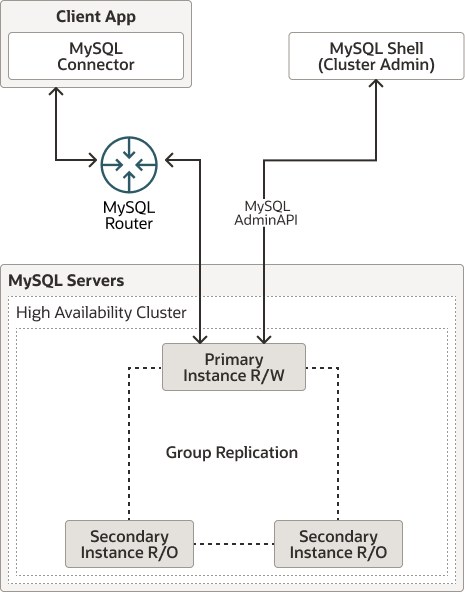
集群架构概览
我们使用的是 一主两从 的 MySQL InnoDB Cluster:
- 主节点:node12
- 从节点:node15、node16
- 路由层:MySQL Router 负责写请求路由到主库
问题1、主节点无法写入数据
问题描述
主节点卡在事务提交阶段,状态为:waiting for handle commit
客户端写入请求经过 MySQL Router 到达主库后,事务无法完成提交。初步判断:由于写入量极大,Raft 日志复制出现阻塞,主库需要等待至少一个从节点完成日志持久化,导致多数派确认延迟。
紧急方案
鉴于数据同步任务紧急,我们决定 先暂停两个从库的同步,待存量数据同步完成后再恢复集群。
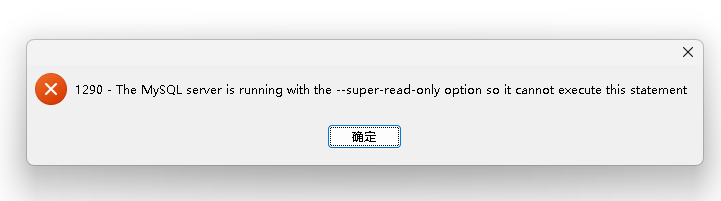
操作后出现新状况:主库进入只读状态,报错如下:
1290 - The MySQL server is running with the --super-read-only option so it cannot execute this statement
临时处理:关闭主库的超级只读模式
先将主库的数据临时设置为可写状态,执行以下命令:
-- 查看当前 super_read_only 状态
SHOW VARIABLES LIKE 'super_read_only';
-- 立即关闭超级只读模式,恢复写入能力
SET GLOBAL super_read_only = OFF;
观察到 MySQL 数据库能正常插入数据了。
旧系统的数据都同步到新系统后,需要将 MySQL 集群环境恢复,又遇到了下面的问题。
问题2、无法获取 MySQL 集群状态
问题描述
先把两个从节点的数据库服务重启下,然后执行以下命令查看 MySQL 集群状态。
var cluster=dba.getCluster()
提示报错:
Dba.getCluster: This function is not available through a session to a standalone instance (metadata exists, instance belongs to that metadata, but GR is not active) (MYSQLSH 51314)
原因
- 节点上存在 InnoDB Cluster 元数据(metadata exists)
- 节点属于该集群元数据(instance belongs to that metadata)
- 但 Group Replication (GR) 当前未激活(GR is not active)
这意味着该节点之前是集群的一部分,但 GR 已停止运行,而 MySQL Shell 拒绝通过未运行 GR 的实例来操作集群。
根本原因
结合之前的错误日志(无法建立 GR 连接),最可能的情况是:
- 节点
node12尝试加入集群但失败了(因为与node15和node16的连接问题) - GR 未能成功启动,但 InnoDB Cluster 的元数据表(
mysql_innodb_cluster_metadata)仍然存在 - MySQL Shell 检测到元数据存在但 GR 不活跃,出于安全考虑拒绝操作。
可能的解决方案
方案一:从其他健康节点获取集群对象
如果集群中有其他节点仍在正常运行 GR,从那个节点连接。
结果:同样报错。
方案二:如果所有节点都离线,需要重建集群
使用重集群的命令:
var cluster = dba.rebootClusterFromCompleteOutage()
结果:遇到新的错误(详见问题三)。
方案三:清理元数据后重新加入(风险高)
手动清理旧元数据后重新加入集群。考虑到风险,暂未执行。
问题3、从节点数据库的部分表没有主键
问题描述
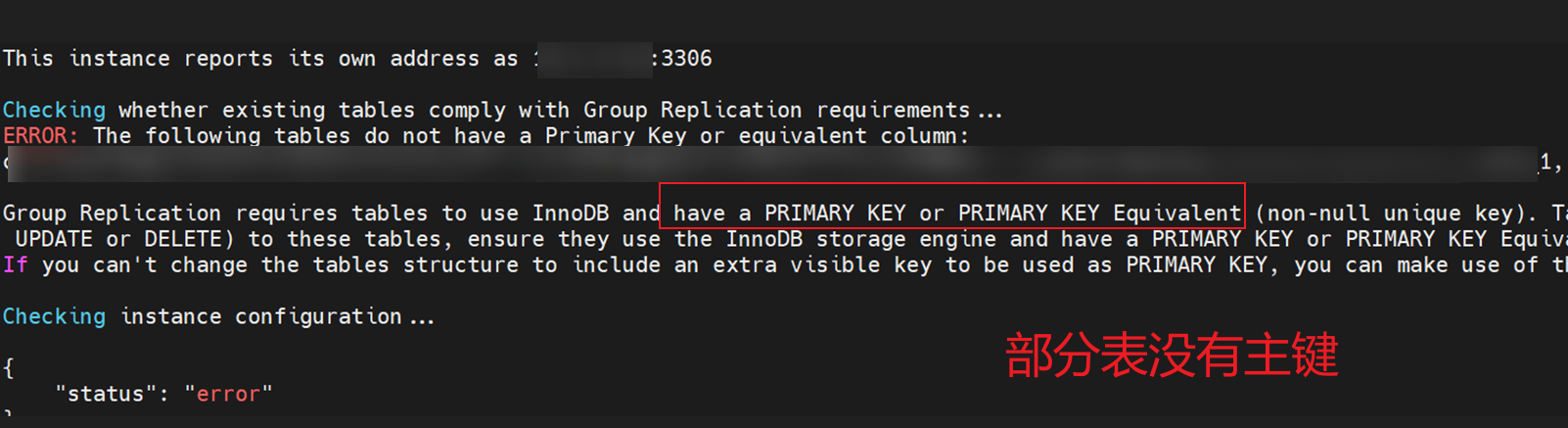
先把两个从节点的数据库服务重启下,然后在主节点node12上执行重集群的命令:
var cluster = dba.rebootClusterFromCompleteOutage()
提示报错:
ERROR: The following tables do not have a Primary Key or equivalent column
解决方案
- 先为主库中缺少主键的表 添加主键
- 使用 MySQL 同步工具同步表结构到从库
- 期间从库可能出现只读状态,同样临时关闭只读模式
主键添加完成后,本以为可以顺利重启集群,结果新的阻碍又出现了。
问题4、重启集群时遇到 GTID 冲突
问题描述
三个节点都补充完主键后,再次在主节点 node12 上执行重启集群命令:
var cluster = dba.rebootClusterFromCompleteOutage();
报错信息如下:

MySQL node12:3306 ssl JS > var cluster = dba.rebootClusterFromCompleteOutage()
Restoring the Cluster 'prod_cluster' from complete outage...
Cluster instances: 'node12:3306' (OFFLINE), 'node12:3306' (OFFLINE), 'node12:3306' (OFFLINE)
Waiting for instances to apply pending received transactions...
WARNING: Detected GTID conflits between instances: 'node12:3306', 'node12:3306', 'node12:3306'
Dba.rebootClusterFromCompleteOutage: To reboot a Cluster with GTID conflits, both the 'force' and 'primary' options must be used to proceed with the command and to explicitly pick a new seed instance. (RuntimeError)
这个错误表明三个节点之间存在 GTID 冲突(GTID conflicts),即各节点的执行事务历史不一致,MySQL Shell 无法自动判断哪个节点拥有最权威的数据。
解决方案
方案一:强制指定主节点重启(不可行)
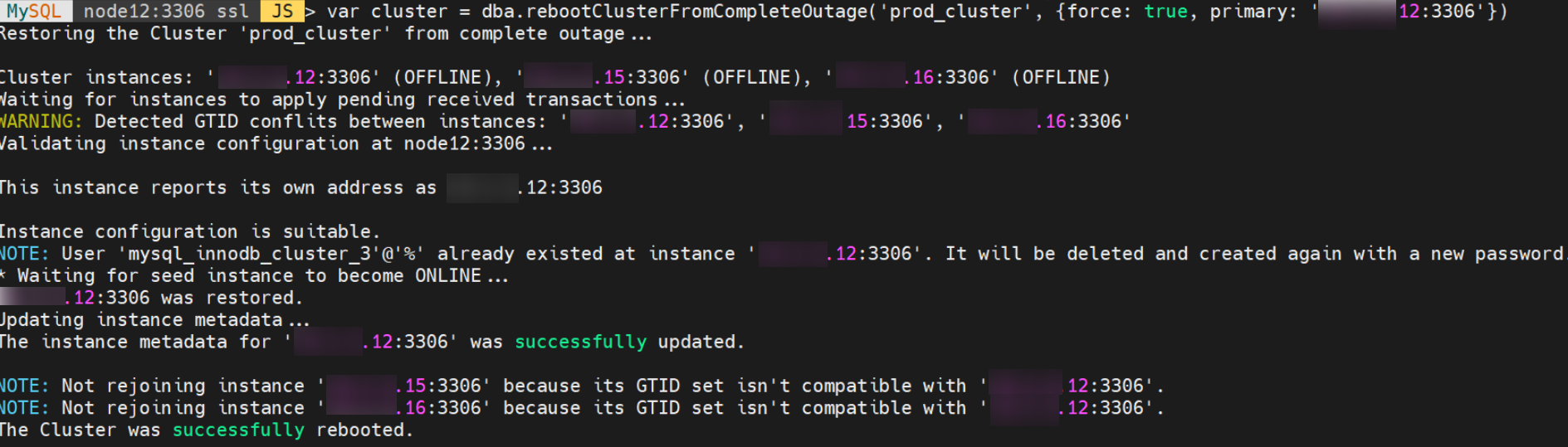
var cluster = dba.rebootClusterFromCompleteOutage('prod_cluster', {force: true, primary: 'node12:3306')
结果:从节点仍报 GTID 冲突,无法加入集群。
提示信息显示两个从节点的 GTID 集合与主节点不兼容。
var cluster = dba.rebootClusterFromCompleteOutage('prod_cluster', {force: true, primary: 'node12:3306'})
Restoring the Cluster 'prod_cluster' from complete outage...
Cluster instances: 'node12:3306' (OFFLINE), 'node15:3306' (OFFLINE), 'node16:3306' (OFFLINE)
Waiting for instances to apply pending received transactions...
WARNING: Detected GTID conflits between instances: 'node12:3306', 'node15:3306', 'node16:3306'
Validating instance configuration at node12:3306...
This instance reports its own address as node12:3306
Instance configuration is suitable.
NOTE: User 'mysql_innodb_cluster_3'@'%' already existed at instance 'node12:3306'. It will be deleted and created again with a new password.
* Waiting for seed instance to become ONLINE...
node12:3306 was restored.
Updating instance metadata...
The instance metadata for 'node12:3306' was successfully updated.
NOTE: Not rejoining instance 'node15:3306' because its GTID set isn't compatible with 'node12:3306'.
NOTE: Not rejoining instance 'node16:3306' because its GTID set isn't compatible with 'node12:3306'.
The Cluster was successfully rebooted.
再次查看集群状态,node15和node16处于 OFFLINE 状态,如下图所示:
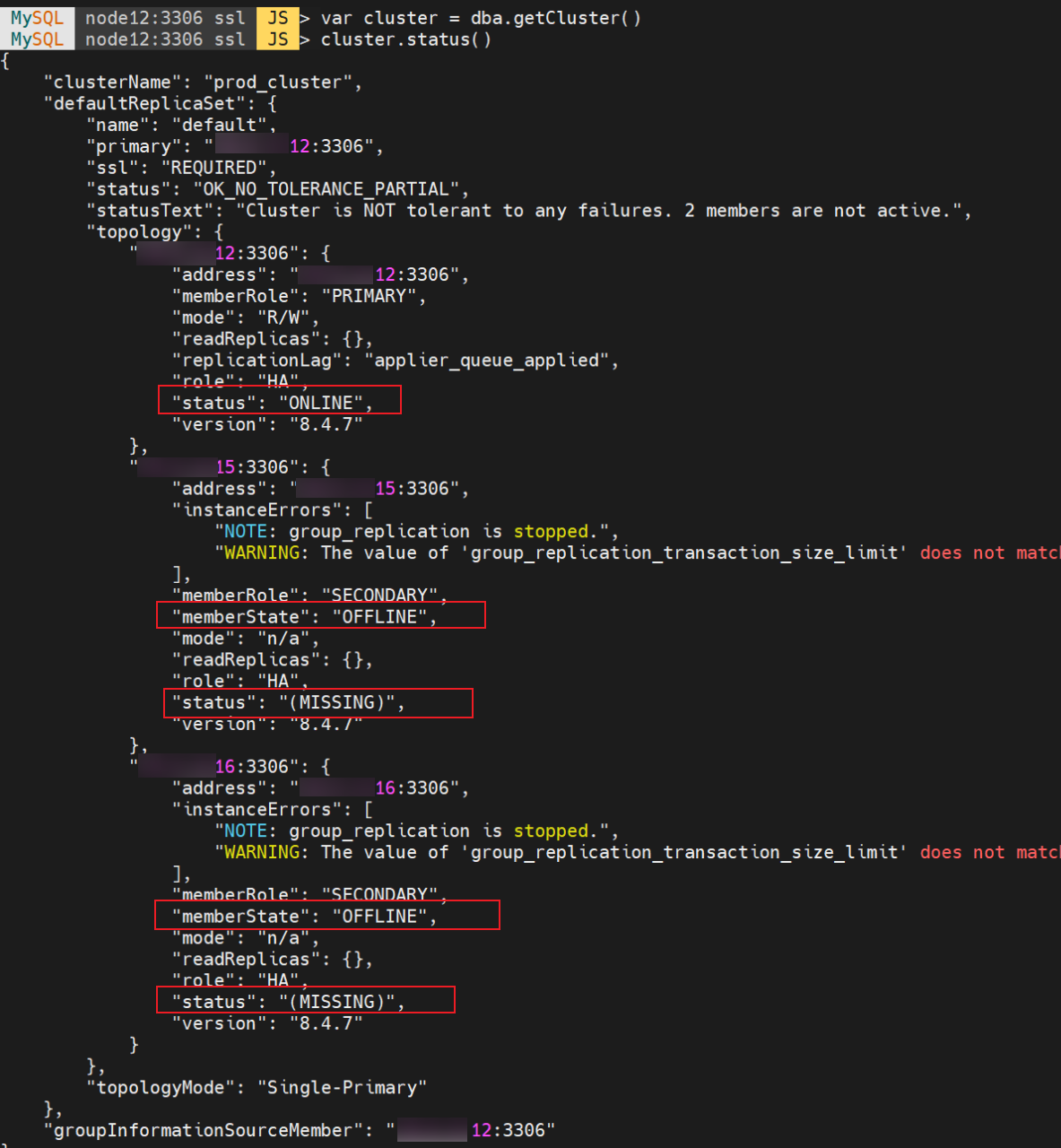
方案二:强制添加 node15 为节点(不可行)
执行效果
不可行,从节点报 GTID 冲突。
执行步骤
(1)执行以下命令讲 node15 加入到集群。
cluster.rejoinInstance('root@node15:3306')
提示 node15 上的 32742543...:14-28 事务在集群上不存在,说明 node15 上单独执行了一些事务。

(2)那就看下 node15 上的 32742543...:14-28 事务是什么。
执行以下命令查看 binlog 的内容
sudo mysqlbinlog --include-gtids='32742543-f82d-11f0-8875-347379d94010:14-28' --base64-output=DECODE-ROWS -v /var/lib/mysql/binlog.000259 | grep -E "(INSERT|UPDATE|DELETE|CREATE|DROP|ALTER|BEGIN|COMMIT)" | head -n 50
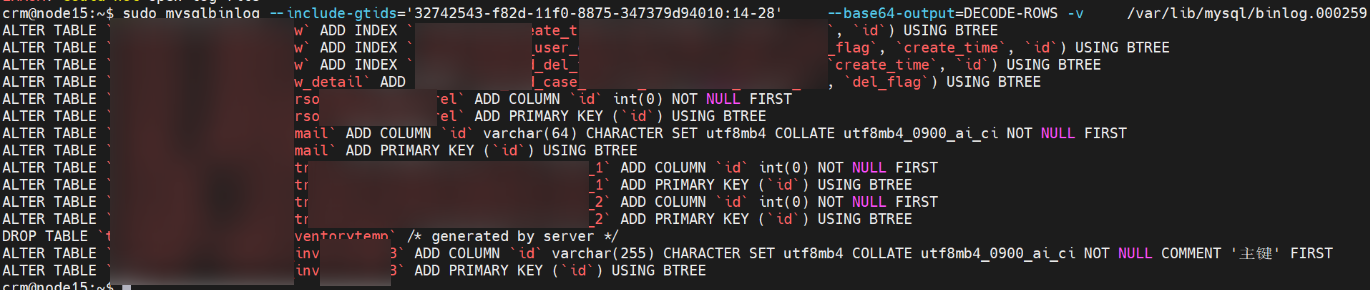
可以看到都是给一些表添加索引。
咦,这不就是问题3出现时我们给表添加索引执行的语句吗?
这些事务是手动执行的 DDL 操作(加主键、删表),而且node12 上也有相同操作,只是 GTID 分配不同导致的不一致。
既然要解决问题3,就不得不手动在其他表添加索引,但是又会造成 GTID 冲突,那如何解决呢?
方案三:重设 GTID
既然操作内容相同,数据逻辑一致,直接强制对齐 GTID 即可。
在 node15 上执行:
STOP GROUP_REPLICATION;
RESET MASTER;
SET @@GLOBAL.GTID_PURGED='187b77e6-f833-11f0-bbb9-347379d94010:1-38820217,32742543-f82d-11f0-8875-347379d94010:1-13';
注意:这里用 1-13 而不是 1-28,因为 14-28 是 errant GTIDs 需要丢弃。
问题5、主从节点的 GTID 差距太大
由于 node15 和 node16已经停止运行很长时间了,和 node12 之间的 GTID 肯定相差很大,那先看下三个节点的 GTID。
最新 GTID 差距状态:
| 节点 | 主要 GTID 范围 |
|---|---|
| node12 | 187b77e6...:1-38837589(+17,372 事务) |
ae4fbecb...:1-6848887(全新 UUID,约 684 万事务) | |
| node15 | 187b77e6...:1-38820217(落后 17,372) |
32742543...:1-28(errant GTID) |
差距很大,手动对齐 GTID 不可行,因为:
- 无法安全设置
GTID_PURGED包含ae4fbecb...(这是 node12 新生成的) - 17,372 个事务差异 + 684 万新域事务,数据不一致
解决方案
最稳妥的方案:clone(推荐)
由于 node12 已经有大量新事务(ae4fbecb...:1-6848887),如果 node15/node16 没有这些,直接用 clone 最省心。
执行步骤:
// 移除旧实例
cluster.removeInstance("node15:3306", { force: true });
cluster.removeInstance("node16:3306", { force: true });
// 用 clone 重新添加(自动同步最新数据)
cluster.addInstance("root@node15:3306", { recoveryMethod: "clone" });
cluster.addInstance("root@node16:3306", { recoveryMethod: "clone" });
移除 node15 的截图如下:

将node12的数据clone到 node15,如下图所示:
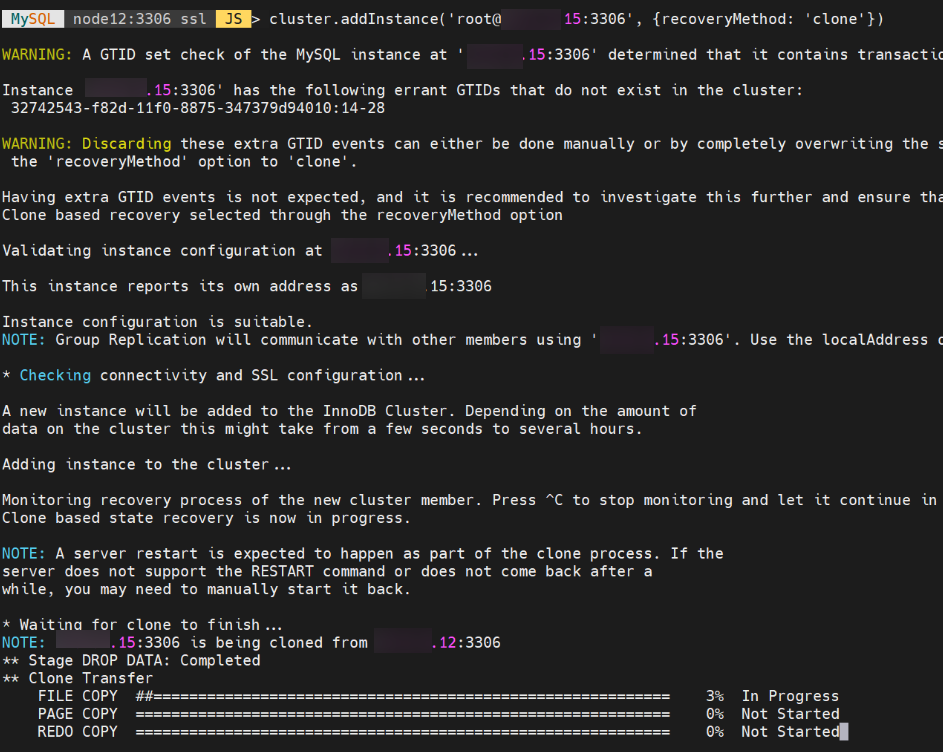
最终clone完成,如下图所示,总共 clone 了 103.96 GB 数据,耗时 24 分钟。
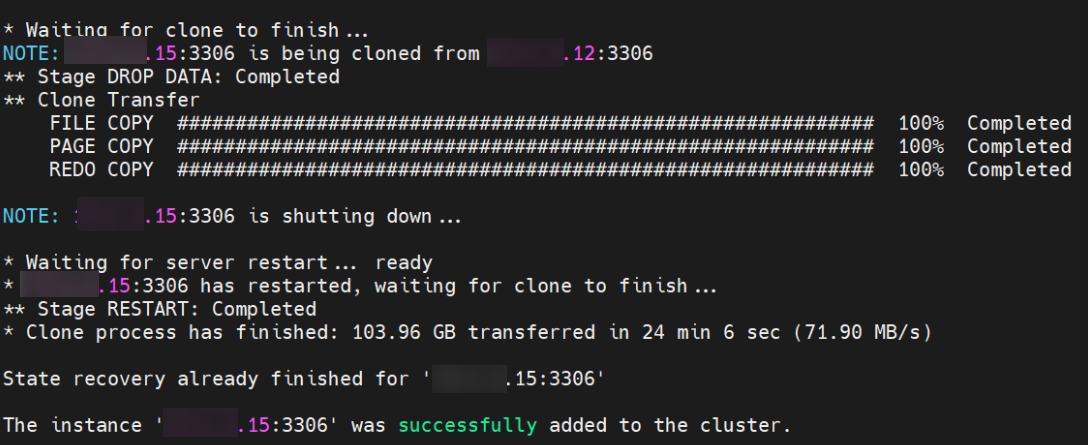
查看集群的状态,node15 状态为 ONLINE,恢复正常。
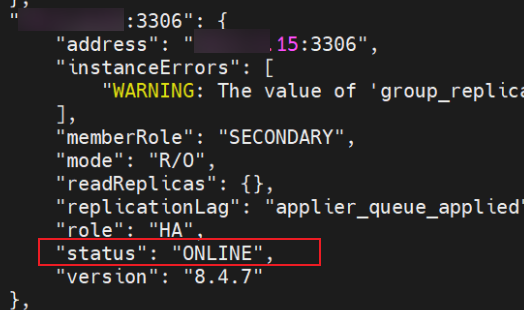
同样的,将node12的数据clone到 node16。
最终验证
在 node12 上执行一条数据更新操作,node15 和 node16 均能实时同步,集群恢复正常 ✅
复盘总结
| 问题编号 | 问题现象 | 核心原因 | 最终解决方案 |
|---|---|---|---|
| 1 | 主节点无法写入,卡在 commit | Raft 日志复制阻塞,多数派确认延迟 | 临时关闭从库 + 关闭 super_read_only |
| 2 | 无法获取集群状态 | GR 未激活,元数据残留 | 尝试重启集群,引出后续问题 |
| 3 | 从节点缺少主键 | 表结构设计缺陷 | 手动添加主键,同步结构 |
| 4 | GTID 冲突 | 手动 DDL 造成 errant GTID | 重设 GTID_PURGED |
| 5 | GTID 差距过大 | 从库长期离线,事务积压 | Clone 重建从节点 |
这次线上故障处置,让我们深刻体会到:
- 集群运维中,GTID 一致性是生命线 —— 任何手动操作都可能留下隐患
- Clone 是处理大差距复制的“后悔药” —— 当 GTID 乱到无法梳理时,重建往往比修补更高效
- 临时措施要有完整的恢复预案 —— 停从库虽然快速解决了写入阻塞,但后续的集群恢复付出了更大代价
希望这次复盘能为你提供一些实战经验。如果觉得有用,欢迎分享给更多朋友~