MySQL 索引优化填坑实录:从1秒到50ms,再到28ms的踩坑与填坑
约 1228 字大约 4 分钟...

一、背景:五一上线的坑
"五一"上线期间,遇到了很多 SQL 查询的性能问题。这次记录一个典型的 SQL 慢查询的踩坑与填坑过程。

二、如何检测到坑
通过数据库监控工具 DBdoctor 可以看到:
- IO 异常
- 具体的 SQL 语句
- 修复建议
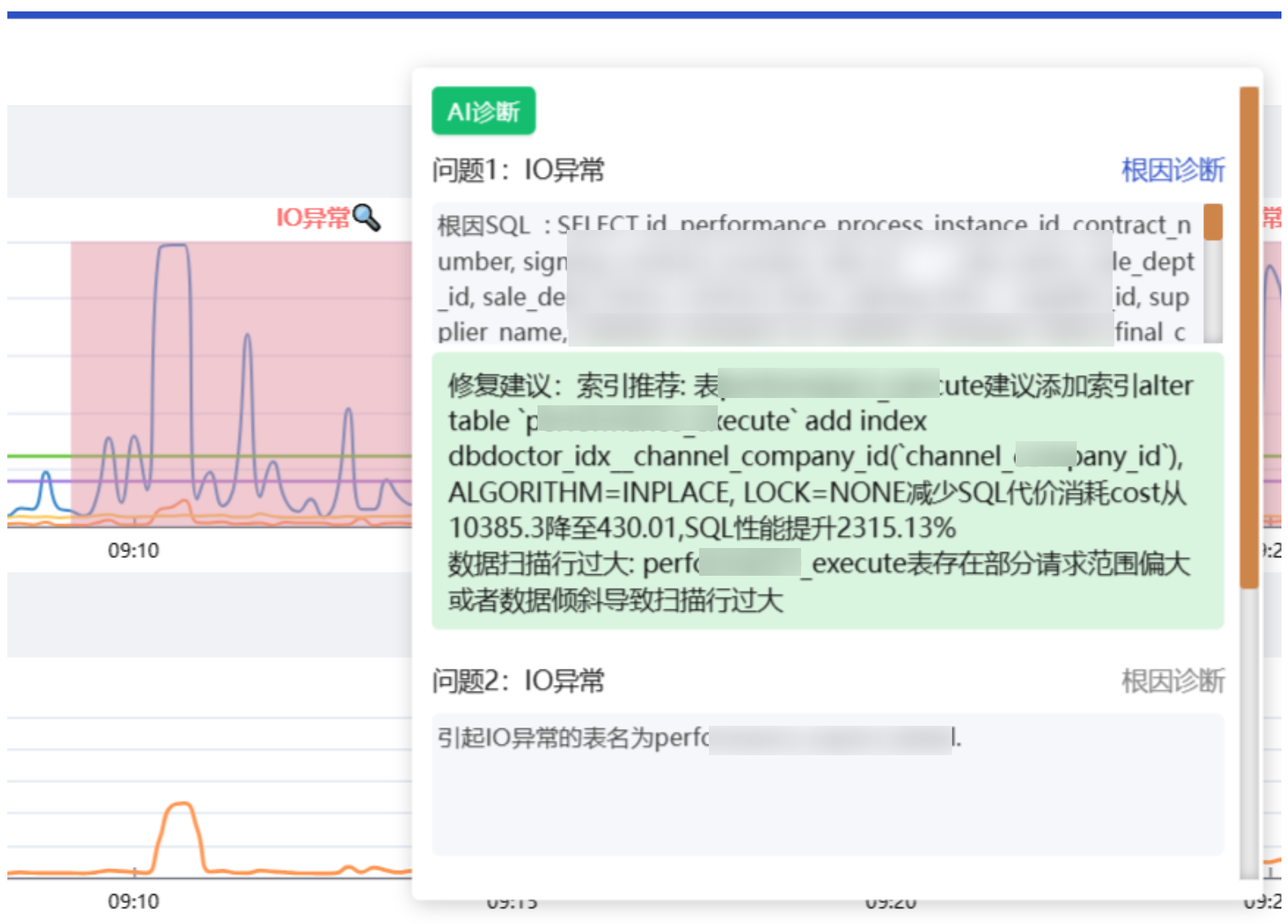
三、根因SQL分析:先找到坑在哪
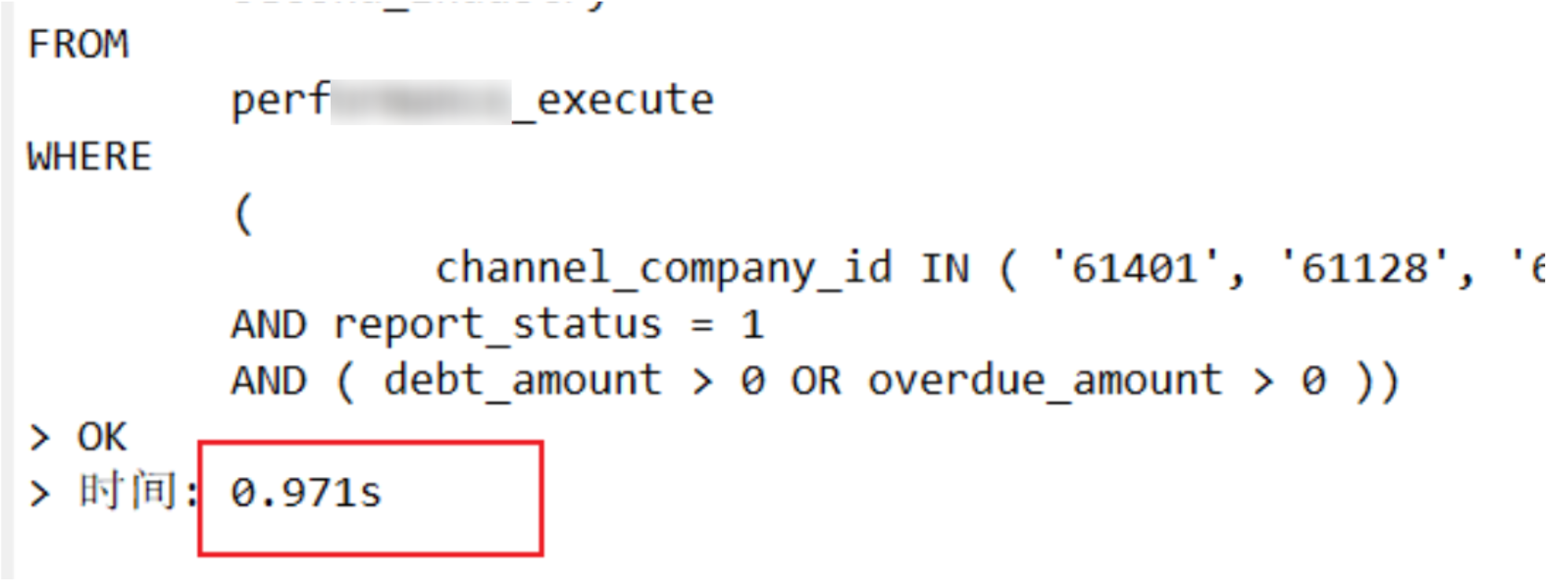
3.1 问题SQL
SELECT
id,
...
FROM perf_execute
WHERE channel_company_id IN (?)
AND report_status = ?
AND (debt_amount > ? OR overdue_amount > ?);
3.2 性能表现
优化前:约1秒
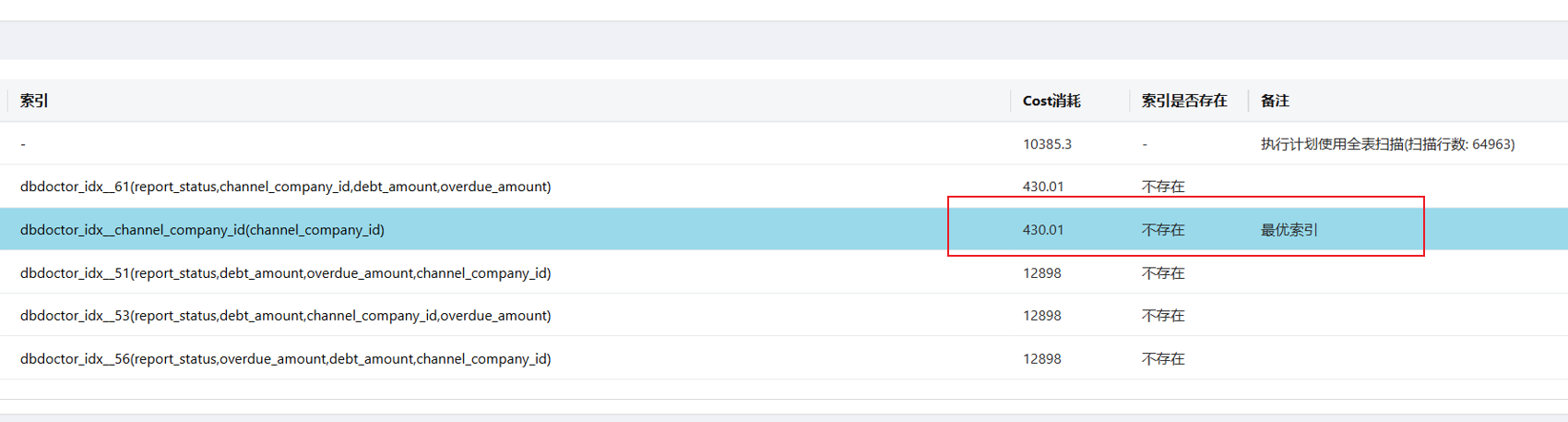
3.3 代价评估
DBdoctor 给出的分析:
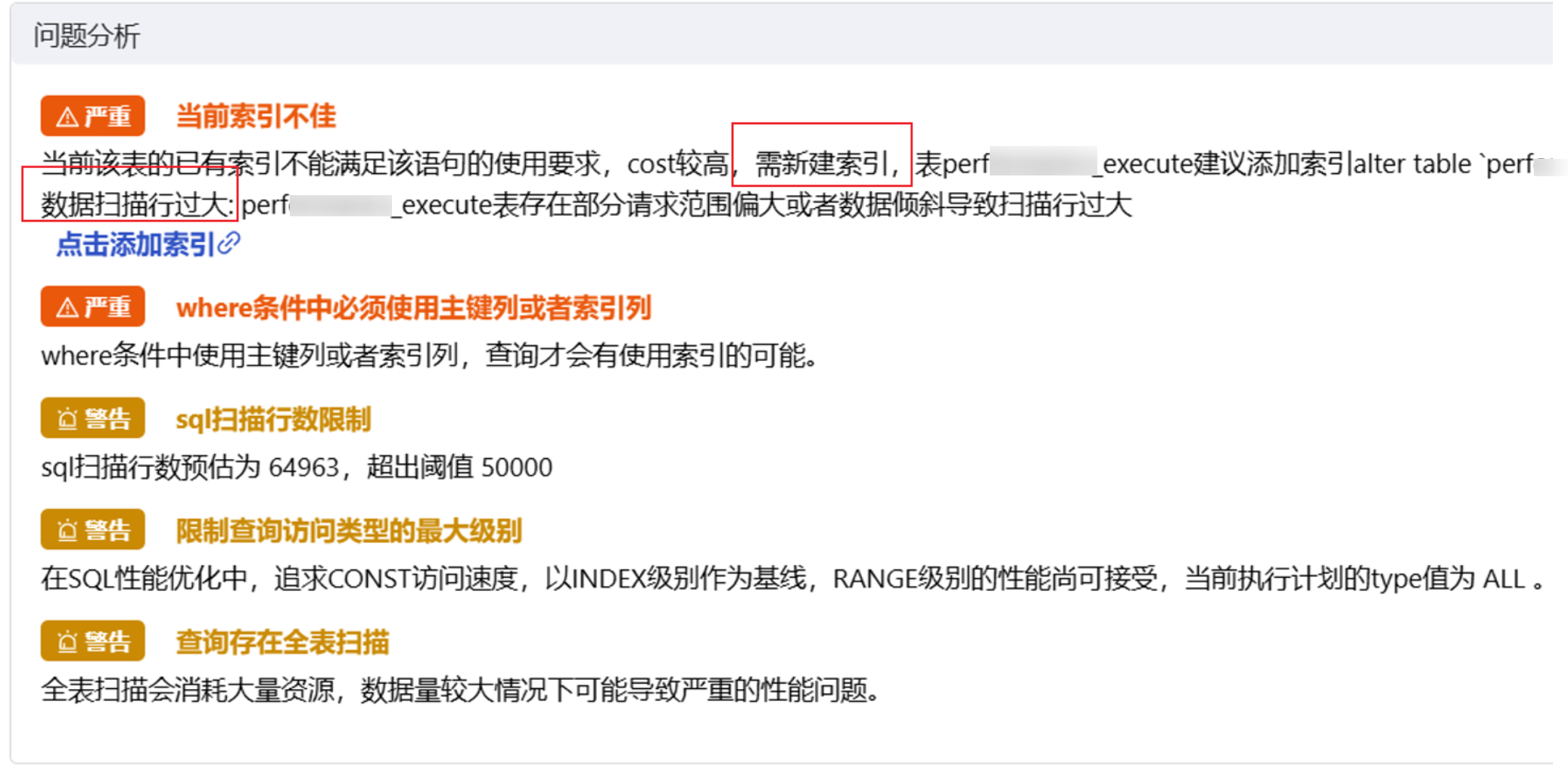
发现的坑:
- 全表扫描,数据扫描行过大
- 存在部分请求范围偏大或者数据倾斜
四、填坑第一回合:单列索引
4.1 填坑方案
DBdoctor 推荐的索引:
ALTER TABLE `perf_execute`
ADD INDEX `dbdoctor_idx__channel_company_id`(`channel_company_id`),
ALGORITHM=INPLACE, LOCK=NONE;
可以减少 SQL 代价消耗 cost 从 10385.3 降至 430.01,SQL 性能提升 2315.13%。
4.2 填坑效果
查询耗时:50ms
4.3 执行计划验证

| 字段 | 值 | 含义 |
|---|---|---|
| id | 1 | 查询中的第1个SELECT |
| select_type | SIMPLE | 简单查询,不包含子查询或UNION |
| table | perf_execute | 操作的表名 |
| type | range | 范围扫描,比全表扫描好,但比ref差 |
| possible_keys | dbdoctor_idx__channel_company_id | 可能使用的索引 |
| key | dbdoctor_idx__channel_company_id | 实际使用的索引 |
| key_len | 259 | 使用的索引长度(字节) |
| ref | (空) | 因为是range类型,没有等值匹配 |
| rows | 393 | 估算需要扫描的行数 |
| filtered | 5.56% | 经过条件过滤后剩余的比例 |
| Extra | Using index condition; Using where | 使用了索引下推和WHERE过滤 |
4.4 填坑后的新坑:filtered 太低
虽然加了索引,但 filtered: 5.56% 说明只填了一半的坑:
- 索引只过滤了
channel_company_id - 剩余条件仍需回表判断
- 随着数据量增长,回表成本会线性上升
填坑经验:别只看"耗时降了",要看 filtered 指标。如果太低,说明还有坑没填完。
五、填坑第二回合:复合索引
5.1 填坑思路
把 report_status、debt_amount、overdue_amount 纳入索引,减少回表。
ALTER TABLE `perf_execute`
ADD INDEX `idx_perf_optimize` (
`channel_company_id`,
`report_status`,
`debt_amount`,
`overdue_amount`
), ALGORITHM=INPLACE, LOCK=NONE;
5.2 填坑效果
查询耗时:28ms

5.3 执行计划对比:填坑前后的变化
| 指标 | 单列索引 | 复合索引 | 填坑效果 |
|---|---|---|---|
| possible_keys | dbdoctor_idx__channel_company_id | dbdoctor_idx__channel_company_id, idx_perf_optimize | 选择更多 |
| key | dbdoctor_idx__channel_company_id | idx_perf_optimize | 更优索引 |
| key_len | 259 | 261 | 多用了2字节,走了更多列 |
| rows | 393 | 390 | 扫描行数略减 |
| filtered | 5.56% | 55.55% | 提升10倍 |
| Extra | Using index condition; Using where | Using index condition | 去掉Using where |
5.4 关键填坑点
| 改善项 | 说明 |
|---|---|
| filtered 5.56% → 55.55% | 索引过滤效率提升10倍,回表后有效数据比例大幅提高 |
| key_len 259 → 261 | 复合索引使用了更多列(report_status 被用上) |
| Extra 简化 | 去掉了 Using where,更多条件在引擎层完成过滤 |
5.5 清理旧坑:删除冗余索引
ALTER TABLE `perf_execute`
DROP INDEX `dbdoctor_idx__channel_company_id`;
减少索引维护开销,节省存储空间。
六、填坑路径总结
| 阶段 | 耗时 | filtered | 坑的状态 |
|---|---|---|---|
| 优化前 | ~1s | - | 全表扫描,大坑 |
| 单列索引 | ~50ms | 5.56% | 填了一半,还有回表坑 |
| 复合索引 | ~28ms | 55.55% | 基本填平,推荐长期方案 |
七、还没填完的坑:OR 条件
当前 filtered: 55.55%,仍有 44.45% 的数据需要回表过滤,瓶颈在于:
(debt_amount > ? OR overdue_amount > ?)
MySQL 的坑:OR + 两个范围列无法同时在索引中高效利用。
方案A:接受现状(推荐,如果性能已满足)
当前 50ms 已很好,复合索引已大幅优化。55.55% 的 filtered 在实际生产中是可以接受的。
方案B:继续填坑(如果数据量继续增长)
1. 拆分 OR 为 UNION(改写 SQL)
SELECT id, ... FROM perf_execute
WHERE channel_company_id IN (?)
AND report_status = ?
AND debt_amount > ?
UNION ALL
SELECT id, ... FROM perf_execute
WHERE channel_company_id IN (?)
AND report_status = ?
AND overdue_amount > ?
AND debt_amount <= ?;
配合两个单列/复合索引,每条子查询的 filtered 有望接近 100%。
2. 覆盖索引(如果查询列不多)
ALTER TABLE `perf_execute`
ADD INDEX `idx_perf_cover` (
`channel_company_id`, `report_status`,
`debt_amount`, `overdue_amount`,
`id`, `...其他select列`
);
让 Extra 变成 Using index,彻底消除回表。
八、填坑经验总结
8.1 填坑步骤
- 先填最明显的坑:给
channel_company_id加单列索引,快速止血 - 再填深层的坑:加复合索引,提升
filtered,减少回表 - 清理填坑工具:删除冗余索引,减少维护开销
8.2 填坑技巧
| 技巧 | 说明 |
|---|---|
| 别只看耗时 | filtered 指标更能反映索引的真实过滤效率 |
| 复合索引有讲究 | 等值条件在前,范围条件在后 |
| 定期 ANALYZE TABLE | 确保优化器统计信息准确 |
| 监控 filtered | 长期低于 10%,说明还有坑没填 |