MySQL 死锁案例分析:一次由 Gap Lock 引发的死锁
你好,我是悟空。
背景
本文通过一个实际案例来演示 MySQL 死锁是如何产生的,强烈建议你跟着动手做一遍,这样才能真正理解死锁的根因。
这篇文章带你完整看懂:
- MySQL 死锁是怎么产生的
update + insert为什么会互相等待- 什么是
Next-Key Lock - 什么是
Gap Lock - 为什么两个 insert 最后会形成死锁
环境说明:MySQL 版本:8.0.27,隔离级别:REPEATABLE-READ(可重复读),REPEATABLE-READ 是 MySQL InnoDB 的默认隔离级别。
下图是本文的整体概括图,可以更加快速的了解全文。

创建示例数据
建表和初始化数据的 SQL 如下:
create table passjava_test_lock2(a int, b int, c int, primary key(a), key idx_b(b));
insert into passjava_test_lock2 values(10,10,10),(15,15,15),(20,20,20);
select * from passjava_test_lock2;
+-----+-----+-----+
| a | b | c |
+-----+-----+-----+
| 10 | 10 | 10 |
| 15 | 15 | 15 |
| 20 | 20 | 20 |
+-----+-----+-----+
索引情况用表格表示是这样的:
初始状态
┌──────┬────────┬───────────┐
│record│ a (PK) │ b (idx_b) │
├──────┼────────┼───────────┤
│ 1 │ 10 │ 10 │
├──────┼────────┼───────────┤
│ 2 │ 15 │ 15 │
├──────┼────────┼───────────┤
│ 3 │ 20 │ 20 │
└──────┴────────┴───────────┘
演示如何产生死锁
下面是两个会话的 SQL 操作,会话 1 在左边,会话 2 在右边。为了方便复现,我把完整的 SQL 都贴出来了:
会话 1
-- 开启 deadlocks 日志
SET GLOBAL innodb_print_all_deadlocks = ON;
BEGIN
update passjava_test_lock2 set c= 106 where b = 10;
insert into passjava_test_lock2 values(12,12,12)
会话 2
-- 开启 deadlocks 日志
SET GLOBAL innodb_print_all_deadlocks = ON;
BEGIN
update passjava_test_lock2 set c= 206 where b = 15
insert into passjava_test_lock2 values(14,14,14)
commit
时间线如下所示,整个死锁过程大概 5 秒就结束了:
时间线
┌──────┬────────────────────────────┬───────────────────────────┐
│ STEP │ SESSION 1 │ SESSION 2 │
├──────┼────────────────────────────┼───────────────────────────┤
│ 1 │ BEGIN │ BEGIN │
├──────┼────────────────────────────┼───────────────────────────┤
│ 2 │ UPDATE b=10 → 成功 │ │
├──────┼────────────────────────────┼───────────────────────────┤
│ 3 │ │ UPDATE b=15 → 成功 │
├──────┼────────────────────────────┼───────────────────────────┤
│ 4 │ INSERT (12,12,12) → 等待中 │ │
├──────┼────────────────────────────┼───────────────────────────┤
│ 5 │ │ INSERT (14,14,14) → 死锁! │
├──────┼────────────────────────────┼───────────────────────────┤
│ 6 │ 5秒后成功 │ 回滚 │
└──────┴────────────────────────────┴───────────────────────────┘

最后真的发生了死锁,会话 2 直接报错:
Deadlock found when trying to get lock; try restarting transaction
锁情况分析
下面我们来逐步分析每个步骤持有的锁,这是理解死锁的关键。
步骤 1 和 2:两个会话分别执行 BEGIN
这个没什么好说的,BEGIN 只是开启事务,此时还没有任何锁。
步骤 3:会话 1 执行 update
执行 SQL:
update passjava_test_lock2 set c= 106 where b = 10;
执行结果:Affected rows: 1, Time: 0s
执行完之后,锁的情况是这样的:
passjava_test_lock2 TABLE IX
passjava_test_lock2 idx_b RECORD X 10, 10
passjava_test_lock2 PRIMARY RECORD X,REC_NOT_GAP 10
passjava_test_lock2 idx_b RECORD X,GAP 15, 15
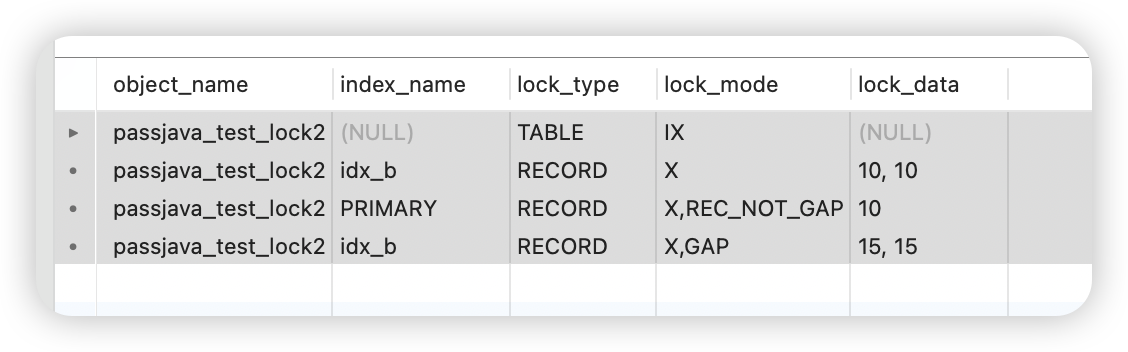
用大白话解释一下:
| 索引 | 锁类型 | lock_mode | lock_data | 锁住的范围(大白话) |
|---|---|---|---|---|
| 表 | TABLE | IX | NULL | 意向写锁,占个坑 |
| idx_b | RECORD | X | 10, 10 | Next-key 锁,锁住 (负无穷, 10] |
| PRIMARY | RECORD | X,REC_NOT_GAP | 10 | 主键记录锁,锁住 a=10 这一行 |
| idx_b | RECORD | X,GAP | 15, 15 | 纯 GAP 锁,锁住 (10, 15) 这个间隙 |

等等,为什么
update b=10会锁住b=15前面的间隙?因为在 REPEATABLE-READ 隔离级别下,InnoDB 为了防止幻读,对于非唯一索引的等值查询(
b=10),不仅会锁住查到的记录及其前面的间隙,还会额外锁住下一个不同值(b=15)前面的间隙。这么说吧,用非唯一索引
b=10做 update,InnoDB 害怕别人在你附近插入新数据导致幻读,所以不仅锁住了b<=10的区域,还提前把(10, 15)这段空隙也锁上了。这个"空隙锁"在日志里就显示成lock_data = 15,15,锁模式是X,GAP。
步骤 4:会话 2 执行 update
执行 SQL:
update passjava_test_lock2 set c= 206 where b = 15;
执行结果:Affected rows: 1, Time: 0s
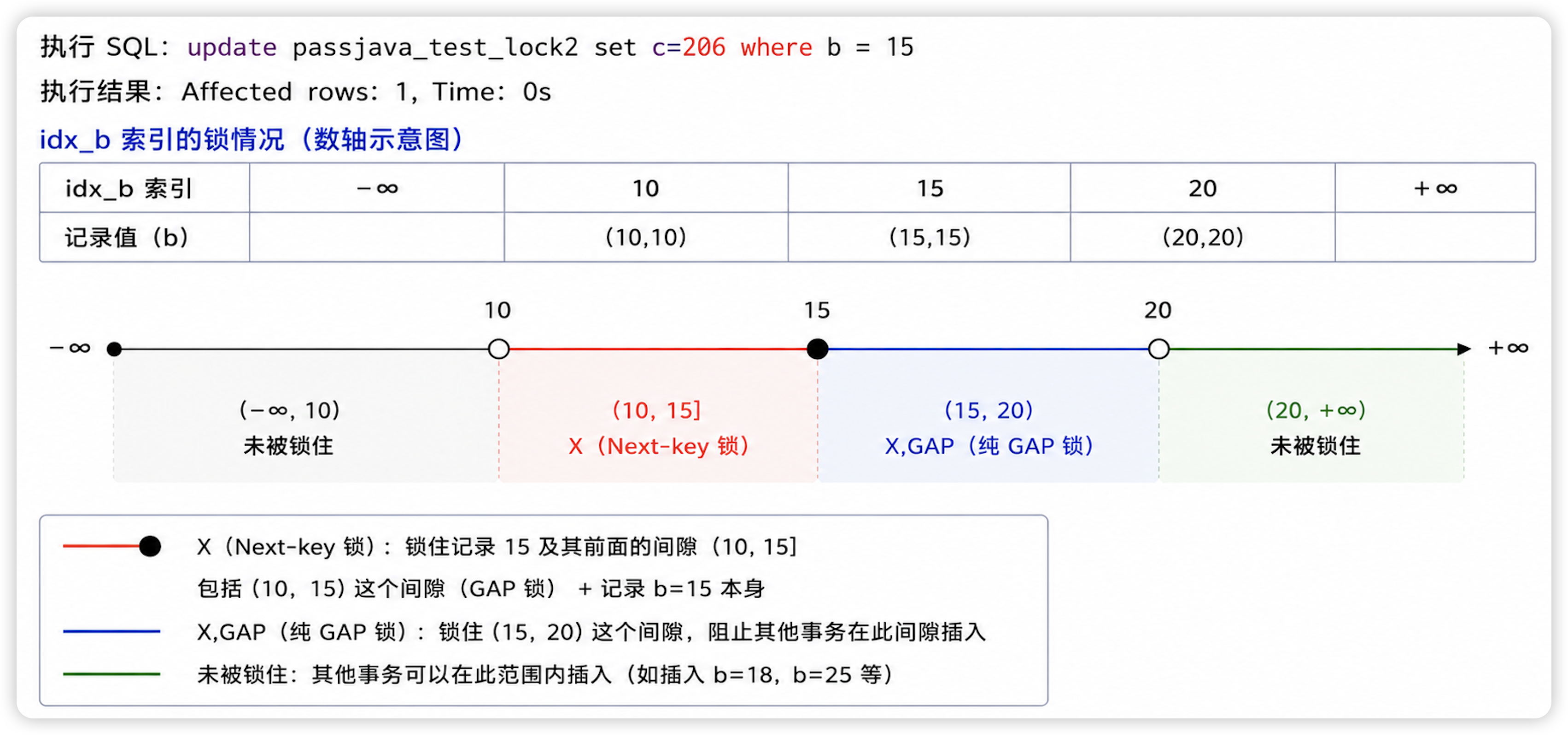
锁的情况:
| 索引 | 锁类型 | lock_mode | lock_data | 锁住的范围(大白话) |
|---|---|---|---|---|
| 表 | TABLE | IX | NULL | 意向写锁,占个坑 |
| idx_b | RECORD | X | 15, 15 | Next-key 锁,锁住 (10, 15] |
| PRIMARY | RECORD | X,REC_NOT_GAP | 15 | 主键记录锁,锁住 a=15 这一行 |
| idx_b | RECORD | X,GAP | 20, 20 | 纯 GAP 锁,锁住 (15, 20) 这个间隙 |
注意看,事务 2 锁住了 (15, 20) 这个间隙。
步骤 5:会话 1 执行 insert
执行 SQL:
insert into passjava_test_lock2 values(12,12,12);
执行结果:等待中
此时事务 1 正在等待的锁:
| 索引 | lock_mode | lock_data | 说明 |
|---|---|---|---|
| idx_b | X,GAP,INSERT_INTENTION (waiting) | 15, 15 | 想在 (10,15) 间隙里插入,但被阻塞 |
事务 1 想插入 b=12,必须在 (10,15) 间隙上加插入意向锁。但这个间隙已经被事务 2 的 Next-key 锁(包含同一个间隙的 GAP 锁)占着。InnoDB 规定:插入意向锁必须等所有已有的 GAP 锁释放才能获得。所以事务 1 只能等。
所以事务 1 的状态是:LOCK WAIT,等的是 X,GAP,INSERT_INTENTION 这个请求被批准。
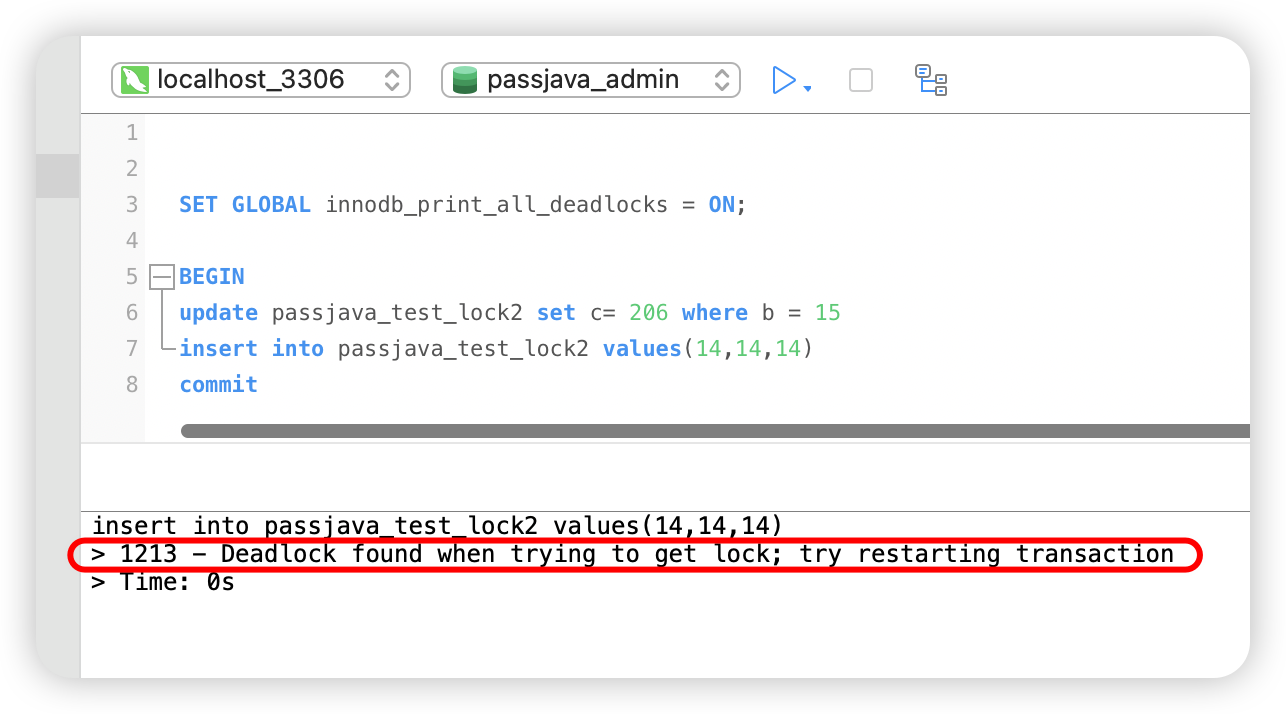
步骤 6:会话 2 执行 insert
执行 SQL:
insert into passjava_test_lock2 values(14,14,14);
执行结果:报错 dead lock
Deadlock found when trying to get lock; try restarting transaction
步骤 7:会话 1 执行成功
事务 1 在等待 5 秒后,事务 2 回滚了,事务 1 终于拿到了锁,执行成功:
Affected rows: 1, Time: 5s
Dead Lock 日志分析
死锁发生之后,我们可以查看死锁日志来验证我们的分析:
$ sudo tail -100 /usr/local/mysql/data/mysqld.local.err
TRANSACTION 2766242, ACTIVE 15 sec inserting
mysql tables in use 1, locked 1
LOCK WAIT 5 lock struct(s), heap size 1128, 4 row lock(s), undo log entries 2
MySQL thread id 12, OS thread handle 6162132992, query id 1194 localhost 127.0.0.1 root root update
insert into passjava_test_lock2 values(12,12,12)
RECORD LOCKS space id 501 page no 5 n bits 72 index idx_b of table `passjava_admin`.`passjava_test_lock2` trx id 2766242 lock_mode X locks gap before rec
Record lock, heap no 3 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 4; hex 8000000f; asc ;;
1: len 4; hex 8000000f; asc ;;
RECORD LOCKS space id 501 page no 5 n bits 72 index idx_b of table `passjava_admin`.`passjava_test_lock2` trx id 2766242 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 4; hex 8000000f; asc ;;
1: len 4; hex 8000000f; asc ;;
TRANSACTION 2766243, ACTIVE 11 sec inserting
mysql tables in use 1, locked 1
LOCK WAIT 5 lock struct(s), heap size 1128, 4 row lock(s), undo log entries 2
MySQL thread id 13, OS thread handle 6163247104, query id 1198 localhost 127.0.0.1 root root update
insert into passjava_test_lock2 values(14,14,14)
RECORD LOCKS space id 501 page no 5 n bits 72 index idx_b of table `passjava_admin`.`passjava_test_lock2` trx id 2766243 lock_mode X
Record lock, heap no 3 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 4; hex 8000000f; asc ;;
1: len 4; hex 8000000f; asc ;;
RECORD LOCKS space id 501 page no 5 n bits 72 index idx_b of table `passjava_admin`.`passjava_test_lock2` trx id 2766243 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 4; hex 8000000f; asc ;;
1: len 4; hex 8000000f; asc ;;
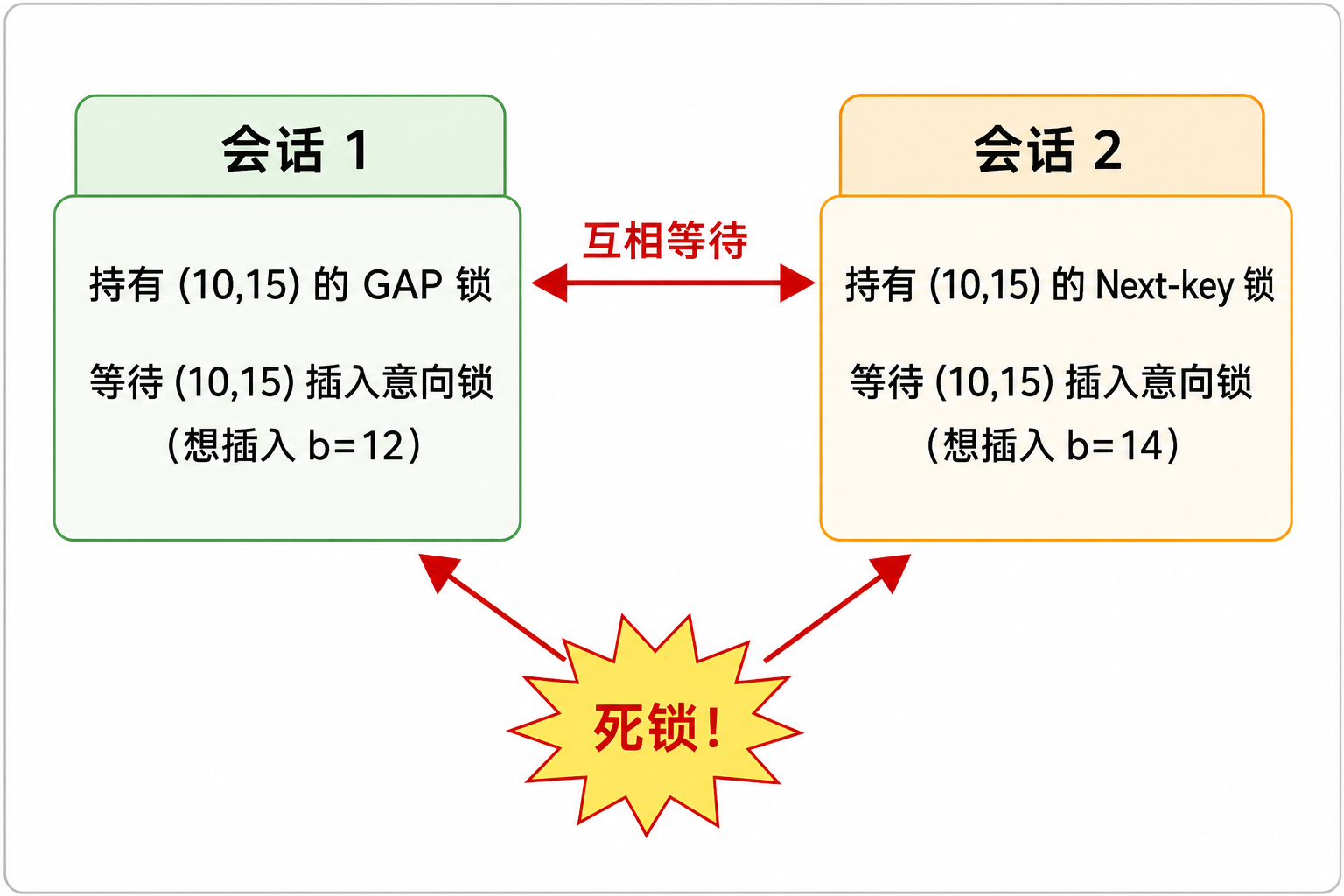
日志分析:
- 会话 1 持有
(10, 15)的 GAP 锁(来自X,GAPon 15,15) - 会话 2 持有
(10, 15]的 Next-key 锁(包含 GAP(10,15)+ 记录锁 on 15) - 两者都想要在
(10,15)间隙上获得插入意向锁来插入自己的数据(12 和 14) - GAP 锁之间虽然兼容,但插入意向锁必须等待所有 GAP 锁释放,所以互相等 → 死锁
总结
回过头看这个死锁案例,核心原因就一句话:两个事务在非唯一索引上更新不同行时,互相把对方的 GAP 锁区域给锁了,然后双方都想插入数据,形成循环等待。
如果你想避免这种死锁,可以考虑:
- 使用唯一索引:如果
b字段换成唯一索引,就不会触发 Next-key 锁,只会锁住那一条记录。 - 调整隔离级别:改成 READ COMMITTED 隔离级别,GAP 锁的行为会不一样。
- 保持操作顺序一致:如果多个事务都要对多条记录加锁,尽量按相同顺序来。
好了,死锁案例就讲到这里。有问题欢迎留言讨论。