RAG 基础知识
RAG 原理简介RAG,中文叫检索增强生成,你可以理解为是开卷考试。我们在考试时,遇到不会的问题,去翻一下书,找到相关内容,然后根据书上内容答题。这个过程的重点是找到相关内容。在 RAG 搜索中,最基础的确认相关性的技术就是向量相似度匹配,英文叫 embedding
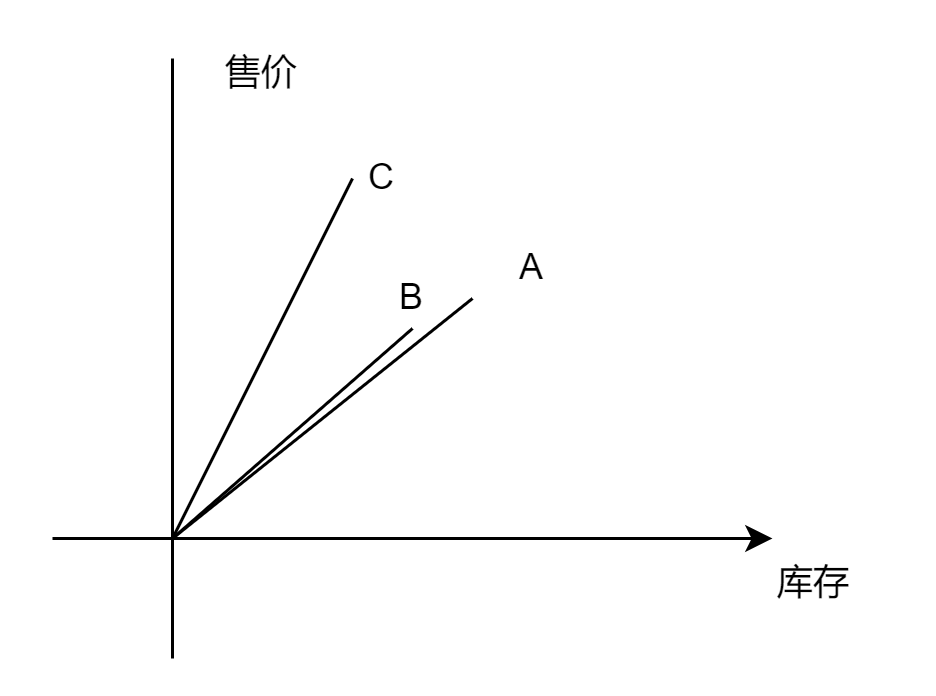
在坐标系上,A、B、C 与横轴之间都会产生一个夹角,我们只需要比较这三个夹角的 cosin 值,就可以知道谁和谁更加接近。这个方法叫做余弦相似性,是向量相似性算法中特别常用的一种。
此外,当我们使用 RAG 技术时,为了避免文本过长,导致超出大模型的上下文限制,是需要对文本进行切割,然后一段一段地进行向量化,存入到向量数据库当中的。常用的切割方法有按段落长度切割、按标题切割等,我们会在后面的项目中陆续了解。
接下来就是将文本转向量以及入向量数据库,依然是使用 LangChain 封装好的工具。这里转向量的大模型,我们使用通义千问的向量模型 text-embedding-v1。
LangChain 之所以叫做 LangChain,就在于它具有一个核心的语法特性,也就是 chain(链式),就像代码的第 10、11 行一样,通过管道操作符 | ,把代码执行的各个步骤连接起来。
通过 RAG(Retrieval-Augmented Generation,检索增强生成)技术,可以将文本内容转换为向量数据并存储到向量数据库中,然后根据用户的问题与这些向量数据进行相似性比较,提取最相关的结果,并最终通过 LangChain 等工具组织答案。
具体流程如下:
- 文本向量化:首先将文本内容(如文档、文章等)转换为向量表示。这一过程通常使用预训练的嵌入模型(Embedding Model),如 BERT、Sentence-BERT 或 OpenAI 的 text-embedding-ada-002 等,将文本映射到高维向量空间中1。
- 存储到向量数据库:将得到的向量数据存储到向量数据库中,以便后续的检索操作。常见的向量数据库包括 Qdrant、Pinecone、Weaviate 等2。
- 用户问题向量化:当用户提出一个问题时,同样使用相同的嵌入模型将问题转换为向量。
- 相似性匹配:在向量数据库中查找与用户问题向量最接近的文本块(即最相关的文档片段)。常用的方法包括余弦相似度、欧氏距离等3。
- 生成答案:将检索到的相关文本块与用户的问题一起输入到大语言模型(LLM)中,生成最终的答案。这个过程可以通过 LangChain 等框架进行组织和优化4。
通过这样的流程,RAG 技术能够有效地结合外部知识库与大模型的生成能力,从而提高回答的准确性与相关性。
在 RAG(检索增强生成)流程中,涉及到的模型和工具分别负责不同的任务:
1. 将用户问题向量化
模型或工具:
- 嵌入模型(Embedding Model):常用的嵌入模型包括 BERT、Sentence-BERT、GloVe、fastText 等。这些模型能够将文本(包括用户问题)转换为高维向量表示。
- 预训练模型:如 OpenAI 的 text-embedding-ada-002 等,专门用于生成高质量的文本嵌入向量。
工作原理: 这些模型通过深度学习技术,捕捉文本中的语义信息,并将其映射到一个高维向量空间中。每个向量在这个空间中的位置反映了其对应的文本的语义特征。
2. 在向量数据库中进行相似度匹配
工具或组件:
- 向量数据库:如 Qdrant、Pinecone、Weaviate、Milvus 等。这些数据库专门设计用于存储和检索高维向量数据。
- 相似度计算算法:通常内置在向量数据库中,常用的相似度计算方法包括余弦相似度、欧氏距离等。
工作原理:
- 存储阶段:首先,将文本内容通过嵌入模型转换为向量,并将这些向量存储到向量数据库中。
- 检索阶段:当用户问题被转换为向量后,向量数据库会使用内置的相似度计算算法,比较用户问题向量与数据库中存储的向量,找出最相似的向量(即最相关的文本块)。
具体流程示例
- 用户问题向量化:
- 用户输入问题 "什么是 RAG 技术?"。
- 使用 Sentence-BERT 模型将问题转换为向量表示。
- 相似度匹配:
- 将转换得到的用户问题向量发送到向量数据库(如 Pinecone)。
- 向量数据库使用余弦相似度算法,比较用户问题向量与数据库中存储的所有向量。
- 返回最相似的前几个向量对应的文本块。
实际应用中的工具链
- LangChain:可以用于整合上述各个步骤,提供端到端的 RAG 解决方案。LangChain 可以调用嵌入模型进行向量化,并与向量数据库进行交互,最终将检索到的结果输入到大语言模型中进行答案生成。
通过这种分工明确的流程,RAG 技术能够高效地结合外部知识库与大模型的生成能力,提供准确且相关的回答。