蒸馏
其实蒸馏呢,本质上也是微调的一种类型。传统微调是为了让大模型获取一些私域知识,比如股票、医疗等等,这是让大模型的知识面增加了,但没有改变大模型的能力。而蒸馏不一样,蒸馏不光教知识,还要教能力。所谓授之以鱼,不如授之以渔,蒸馏就是要让被训练的模型能够学会教师模型的能力。
我们知道传统的一些快速响应模型,比如 qwen2.5、llama3 等等模型是不带思维链的。但 DeepSeek-R1 模型带有思维链,而且思考能力很强。因此对 DeepSeek-R1 蒸馏的意义就是要让 qwen2.5 等模型也学会思维链,就是这么简单。
当我们拿这些教学数据再去微调小模型时,就可以让小模型学会 DeepSeek-R1:671B 同款的输出回答的模式,这种微调方式叫做监督微调。
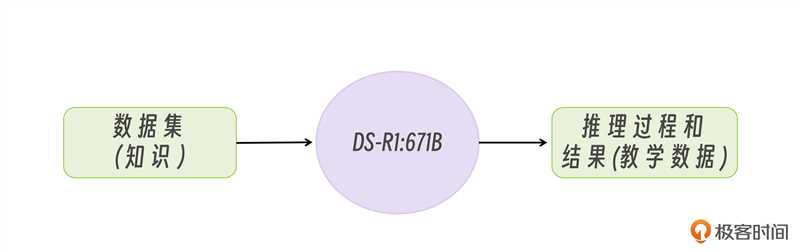
到此,蒸馏的流程就讲完了,整个过程其实非常简单,一点也不神秘,无非就是教学数据的生成与传统微调的教学数据相比,增加了思考过程。
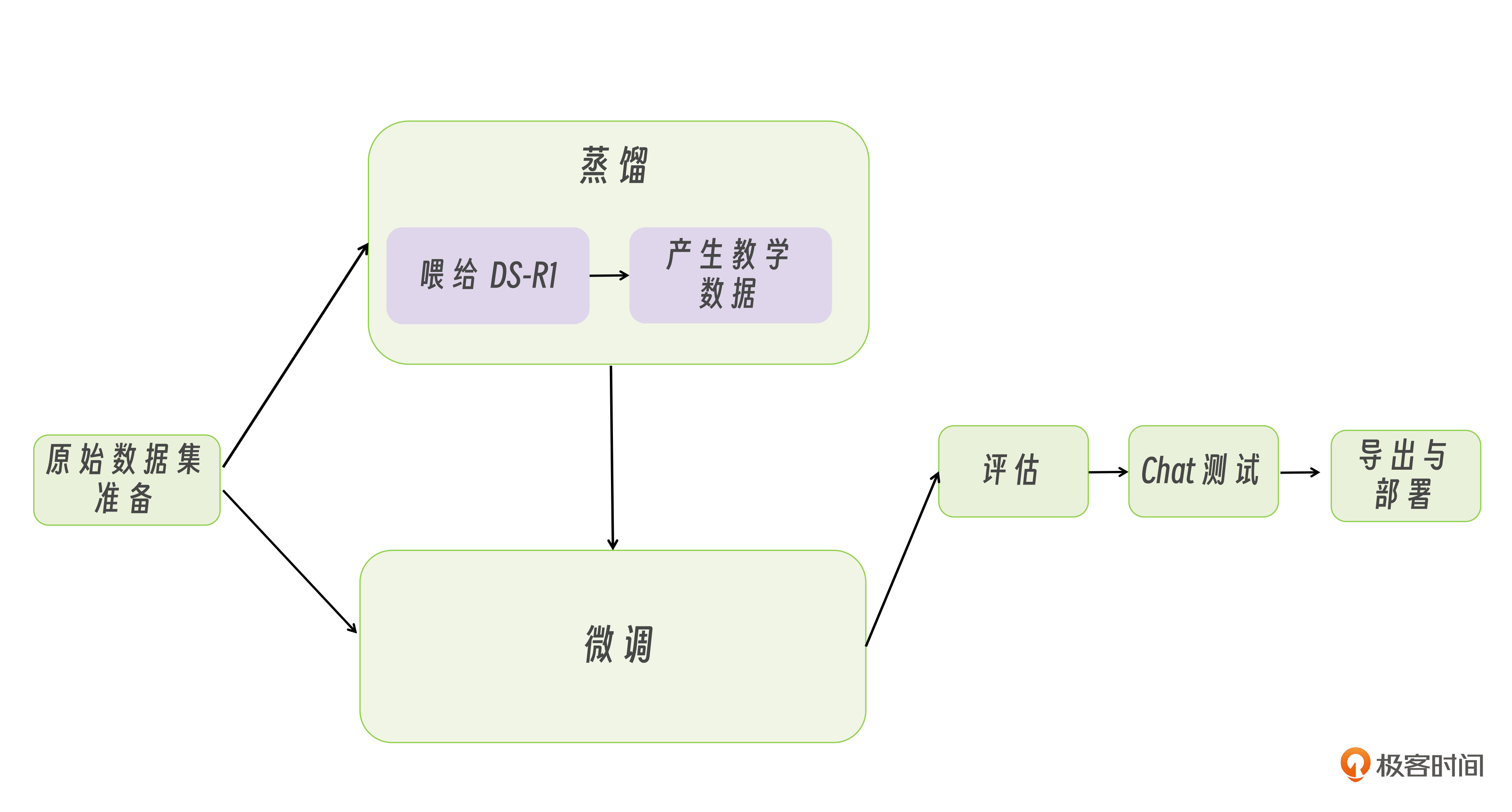
我们完整探讨了大模型落地的核心路径——从不同部署方案的选择,到微调与蒸馏的技术实践,形成了如下图模型开发的全流程知识体系。
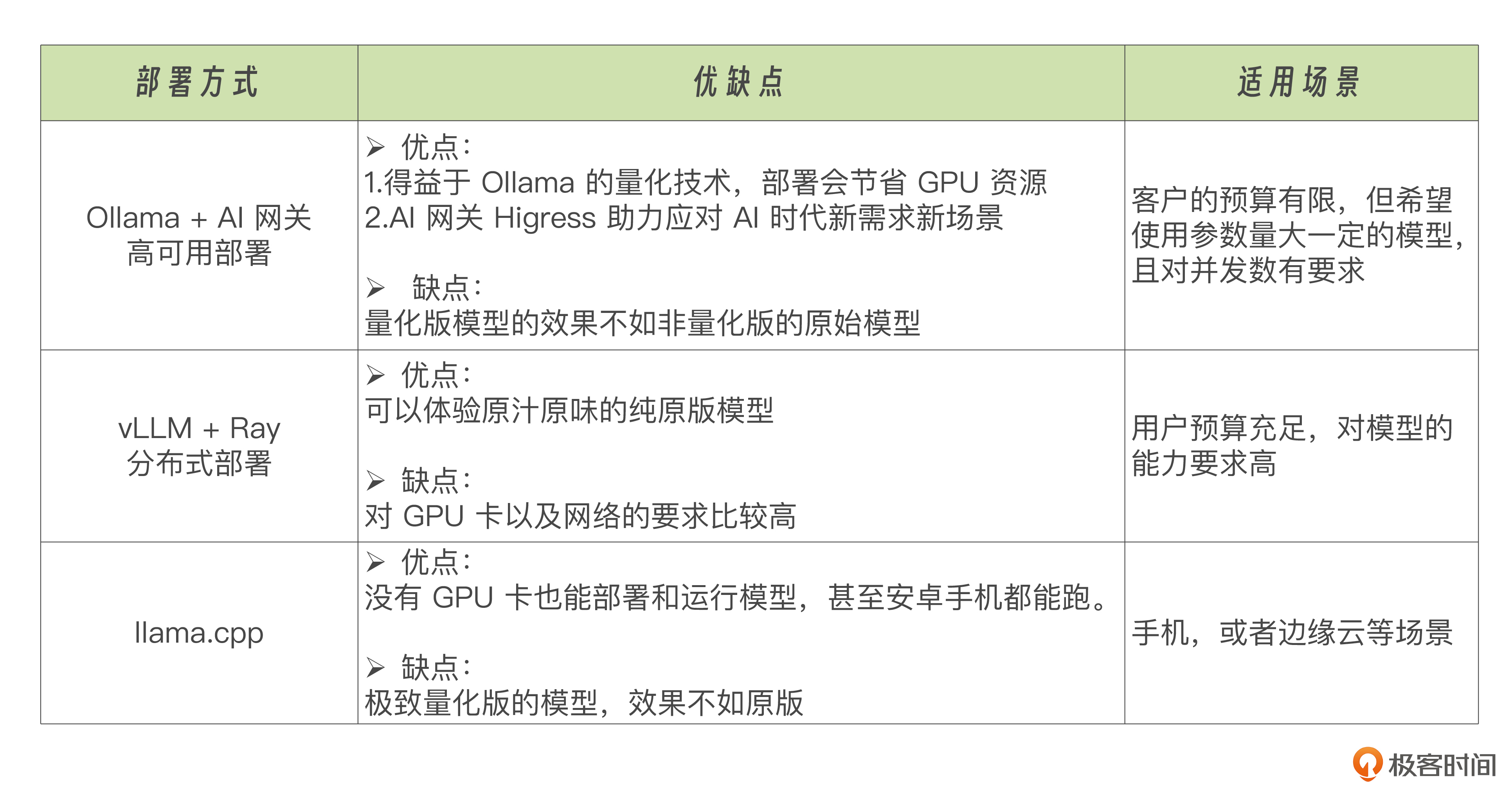
最后,我梳理了一个表格,为大家整理了一下模型部署方案的对比,方便大家学习理解。
问题
1、什么是蒸馏?
先在大模型上跑出带思考过程的数据对,然后喂给小模型,让小模型学会这套方式。
2、化学中的蒸馏和AI领域中的蒸馏的相似处?
在化学实验中,蒸馏是一种用于提纯和分离混合物中不同成分的技术,通过加热混合物,使其中某些成分蒸发,然后再冷凝收集,从而实现分离和提纯的目的。
在AI领域,模型蒸馏(Knowledge Distillation)借鉴了这一概念,其核心思想是将一个复杂、高性能的大模型(教师模型)中的知识或能力提取出来,并传递给一个更小、更高效的模型(学生模型)。具体来说,教师模型的输出(通常是概率分布,即软标签)被用作学生模型的训练目标,通过这种方式,学生模型能够学习到教师模型的决策逻辑和知识,从而在保持较小规模的同时,尽可能地接近教师模型的性能。
这种过程类似于化学中的蒸馏,即从复杂的混合物中提取出纯净的成分,因此得名“模型蒸馏”。
总结
- 蒸馏是一种微调的类型,旨在让被训练的模型学会教师模型的能力,而不仅仅是知识。
- 蒸馏的流程包括准备数据集,将数据喂给大模型以生成教学数据,然后使用监督微调让小模型学会大模型的输出模式。
- 生成教学数据需要根据实际业务情况编写合适的提示词,包括描述需求、规定分类种类、示例以及向大模型提问和反馈答案的代码。
- 教学数据的生成需要懂得业务,写出逼真、符合大模型口吻的示例,以获得良好的效果