RabbitMQ架构简介
你好,我是悟空。
前言
消息队列应该具备五个模块:通信协议、网络模块、存储模块、生产者、消费者。生产者和消费者需要满足通信协议才能和消息队列的 Broker 节点的网络模块通信,完成发送消息和消费消息。Broker节点还需要将消息进行存储和更新。
如下图所示:
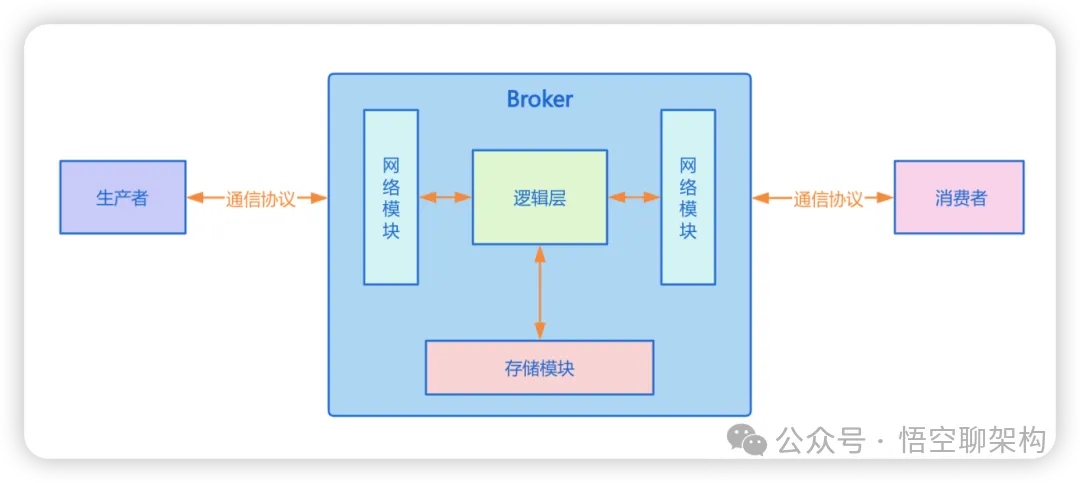
RabbitMQ 系统架构简介
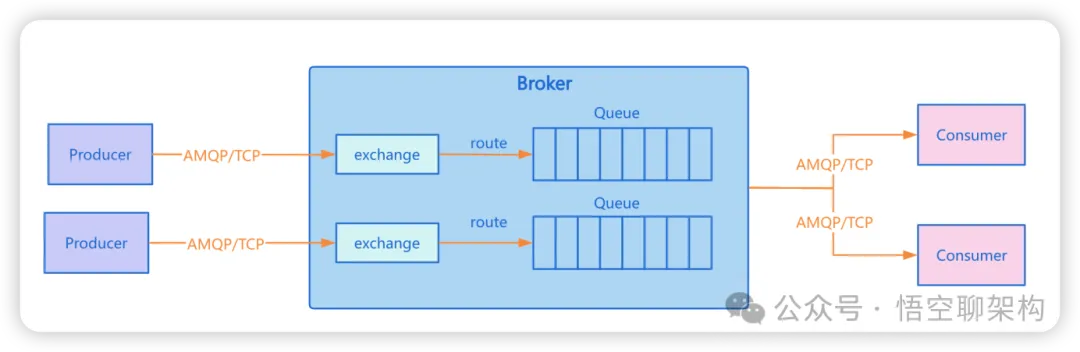
我们先来看下 RabbitMQ 的系统架构,如下图所示:
 img
img
RabbitMQ 由三大模块组成,分别是Producer(生产者)、Broker(代理服务器)、Consumer(消费者)。
Broker 模块概述:
(1)Broker 是整个消息传递系统的核心,负责接收、存储和转发消息,是生产者和消费者之间的桥梁。Broker 内部包含多个关键组件和资源,这些组件协同工作,完成消息的接收、存储、路由和分发等功能。以下是 Broker 中的主要组成部分:
(2)Queue(队列):Queue用来存储消息,支持内存存储或持久化写入磁盘。Broker 负责创建、删除队列。
(3)Exchange(交换器):Exchange 是消息路由的规则引擎,将生产者投递的消息转发到队列。它是一个逻辑上的概念,用来做分发,本身不存储数据。Exchange 根据预设的路由规则,将消息分发到一个或多个队列中。而这个分发的过程被称作 Route(路由),设置路由规则的过程就是 Bind(绑定)。客户端发送消息给 Exchange时会带上 route_key,然后 Exchange 根据不同的路由规则,将数据发送到不同的队列里面。
为了更好的理解 Exchange,下面举一个生活中的例子来加深理解。邮局分拣中心是消息传递系统的一个典型类比,它展示了如何通过路由键和绑定将邮件分发到不同的队列。
角色和组件
- Exchange(交换器):
- 角色:邮局分拣中心。
- 功能:接收来自各个邮递员的邮件,并根据邮件上的地址信息(routing_key)
将邮件分发到不同的邮递区域(Queue)。
- routing_key(路由键):
- 角色:邮件上的地址信息。
- 功能:用于指定邮件的投递目的地。例如,邮件上的收件人地址(如“北京市海 淀区XX路XX号”)就是路由键,它决定了邮件应该被发送到哪个邮递区域。
- Binding(绑定):
- 角色:分拣中心与各个邮递区域之间的连接关系。
- 功能:定义了邮件如何从分拣中心(Exchange)被路由到具体的邮递区域(Queue)。 例如,分拣中心会根据邮件上的地址信息(routing_key)将邮件绑定到对应的邮递区域。
- Queue(队列):
- 角色:邮递区域的邮件存放点。
- 功能:存储分拣中心分发过来的邮件,等待邮递员取走并投递。
具体过程
- 邮件接收:
- 邮递员(生产者)将邮件送到邮局分拣中心(Exchange)。
- 每封邮件都有一个明确的地址信息(routing_key),例如“北京市海淀区XX路 XX号”或“上海市浦东新区XX路XX号”。
- 邮件分拣:
- 分拣中心(Exchange)根据邮件上的地址信息(routing_key)将邮件分发到对应 的邮递区域(Queue)。
例如:如果邮件地址是“北京市海淀区XX路XX号”,分拣中心会将这封邮件绑定(Binding)到“北京市海淀区”对应的邮递区域(Queue)。如果邮件地址是“上海市浦东新区XX路XX号”,分拣中心会将这封邮件绑定到“上海市浦东新区”对应的邮递区域。
- 邮件存储:
- 分拣后的邮件会被放入对应的邮递区域的存放点(Queue)。这些存放点是邮件的临时存储区域,等待邮递员取走。
- 邮件投递:
- 邮递员从对应的邮递区域(Queue)取出邮件,并按照地址信息将邮件投递到收 件人手中。
例子中的对应关系
- 邮件:消息(Message)
- 邮局分拣中心:交换器(Exchange)
- 邮件地址信息:路由键(routing_key)
- 邮递区域:队列(Queue)
- 分拣中心与邮递区域的连接关系:绑定(Binding)
具体场景示例
假设邮局分拣中心有以下三个邮递区域(Queue):
- Queue A:北京市海淀区
- Queue B:上海市浦东新区
- Queue C:通用区域(用于地址不明确的邮件)
- 邮件1:
- 地址(routing_key):北京市海淀区XX路XX号
- 分拣过程:分拣中心(Exchange)根据地址将邮件1绑定(Binding)到 Queue A。
- 结果:邮件1被放入 Queue A,等待邮递员取走。
- 邮件2:
- 地址(routing_key):上海市浦东新区XX路XX号
- 分拣过程:分拣中心(Exchange)根据地址将邮件2绑定(Binding)到 Queue B。
- 结果:邮件2被放入 Queue B,等待邮递员取走。
- 邮件3:
- 地址(routing_key):地址不明确,只有“XX省XX市”
- 分拣过程:分拣中心(Exchange)将邮件3绑定(Binding)到通用区域 Queue C。
- 结果:邮件3被放入 Queue C,等待进一步处理。
这个邮局例子就很好地解释了 Exchange、routing_key、Binding的关系。
注意:RabbitMQ 中的 Topic 是指 Topic 路由模式,表示按模式匹配的路由键转发消息,和消息队列中的 Topic 意义是完全不同的。
Exchange(交换器)有多种类型:
- Direct Exchange:按精确匹配的路由键(routing_key)转发消息。
- Fanout Exchange:将消息广播到所有绑定的队列,不关心路由键。
- Topic Exchange:按模式匹配的路由键转发消息。
- Headers Exchange:基于消息头中的字段进行路由。
RabbitMQ 的网络协议
RabbitMQ 数据流是基于四层 TCP 协议通信的,RabbitMQ 还可以通过插件支持其他协议,如 STOMP、MQTT 和 HTTP,但 AMQP 仍然是其默认和最主要的网络协议。
在协议内容和连接管理方面,遵循 AMQP 规范,上文提到的交换器(Exchange)、交换器类型、绑定(Binding)、路由键(route_key)、队列(Queue)都是遵循 AMQP 协议中的概念。
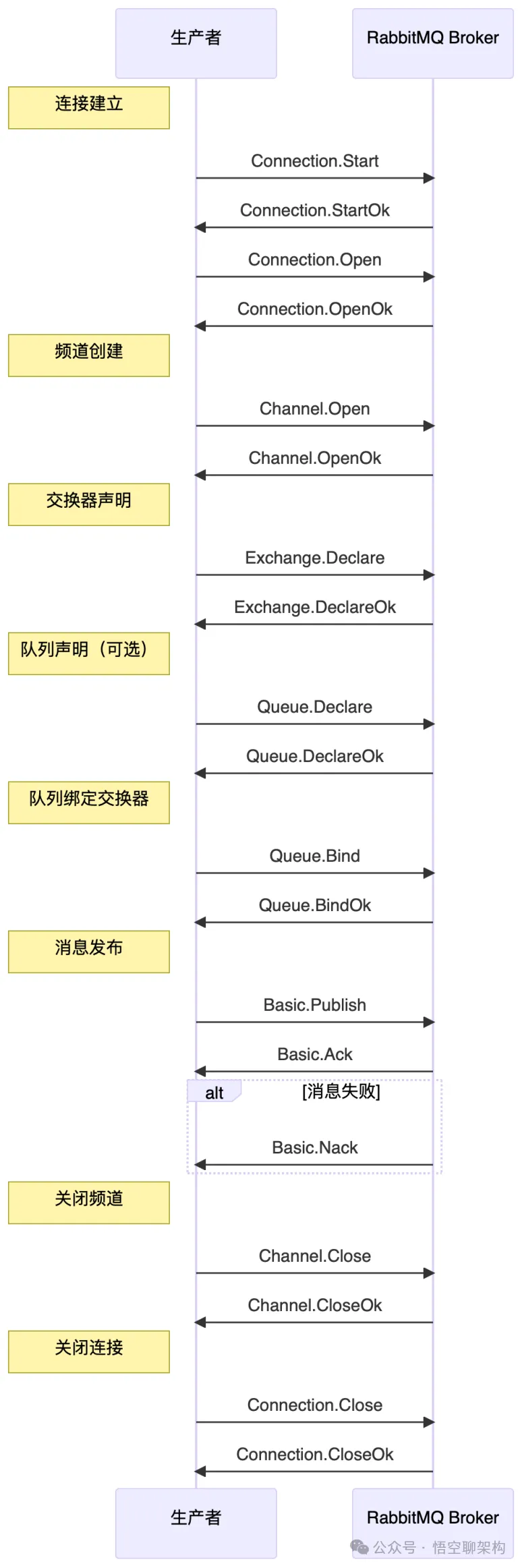
下面以生产者发送消息给 RabbitMQ 时的协议命令交互图,主要包含连接建立、频道创建、交换器声明、队列声明、队列绑定交换器、消息发布、关闭频道、关闭连接这些过程。
 img
img
RabbitMQ 的网络模块
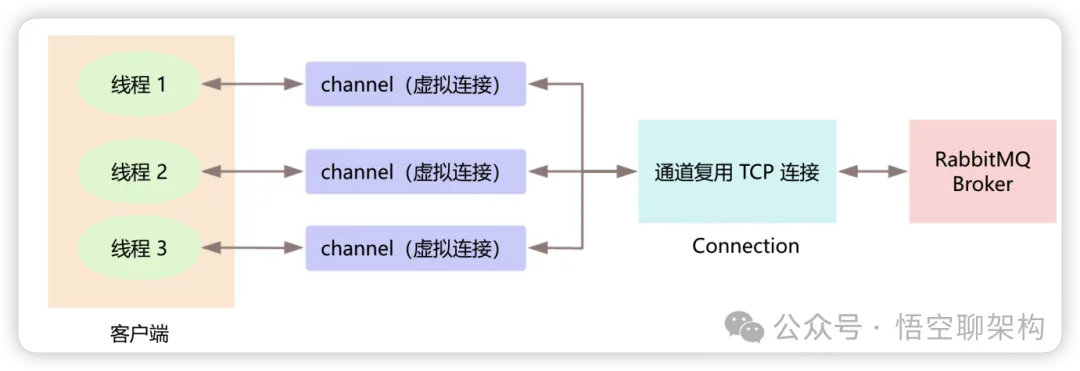
RabbitMQ 的网络层有 Connection 和 Channel 之分,一个消费者或生产者和一个 Broker 通信时会建立一条 TCP 连接,也就是 Connection。一旦 TCP 连接建立成功,消费者或生产者就可以创建一个 AMQP 信道,也就是 Channel。信道是建立在 Connection 之上的虚拟连接,其实每条 AMQP 指令都是通过信道完成的。如下图所示:
 img
img
既生瑜何生亮,有了 Connection 为什么还需要 Channel 呢?
一个应用程序中有很多线程需要和 RabbitMQ 中消费消息或者生产消息,那么就需要和 Broker 建立多个 Connection,也就是多个 TCP 连接,对于操作系统而言,建立和销毁 TCP 连接是非常昂贵的开销,可能会给 Broker 服务器带来很大的性能问题,RabbitMQ 采用类型 NIO(Non-blocking I/O)的方式,也就是 TCP 连接复用,创建了多个虚拟连接(Channel),减少了性能开销,而且也方便管理 TCP 连接。
“
✏️提示:NIO,也称非阻塞 VO,包含三大核心部分: Channel (信道)、 Buffer (缓冲区)和 Selector (选择器)。 NIO 基于 Channel 和 Buffer 进行操作,数据总是从信道读取数据到缓冲区中,或者从缓冲区写入到信道中。 Selector 用于监听多个信道的事件(比 如连接打开,数据到达等) 。 因此,单线程可以监听多个数据的信道。
RabbitMQ 存储
RabbitMQ 的存储分为两个部分:元数据存储和消息数据存储。
元数据存储的原理
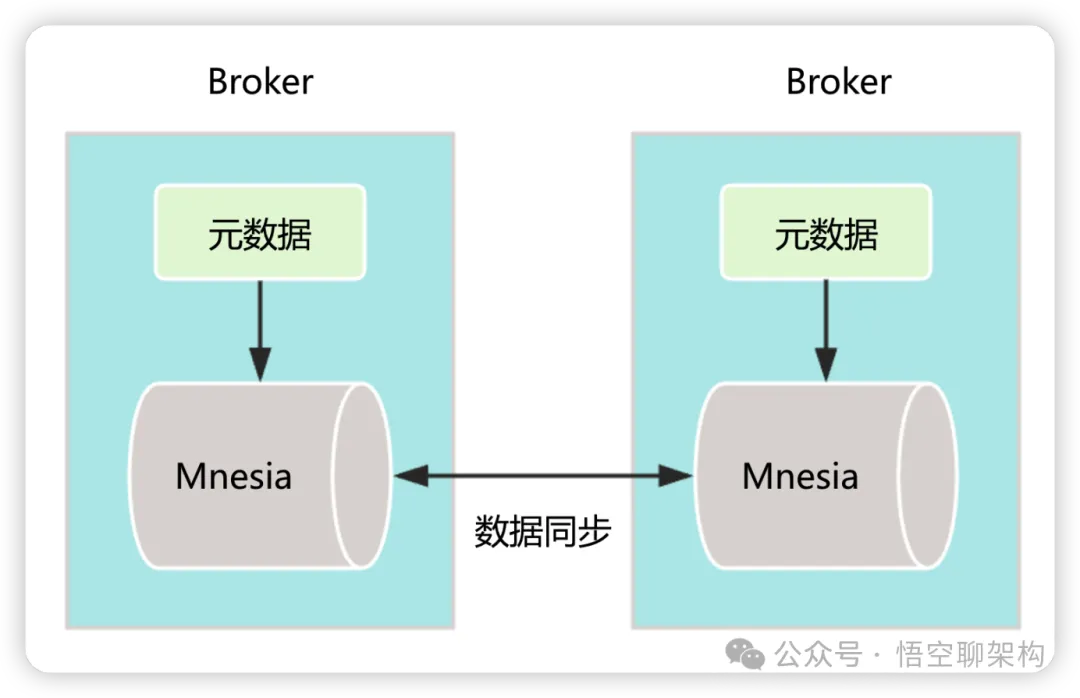
元数据存储的原理如下图所示,RabbitMQ 的每个 Broker 中都有一个 Mnesia,它是一个强大的分布式实时数据库管理系统,具备多节点数据库同步的机制。每个 Mnesia 都保存了一份完整的元数据。
 img
img
既然是分布式数据库,那一定会有分布式系统中的常见问题,如数据同步出现问题造成RabbitMQ 中的Mnesia数据库中的数据不一致,可能会导致集群出现脑裂、无法启动的问题,就只能手动修复异常的 Mnesia 实例上数据。
更多mnesia 的介绍:https://www.erlang.org/doc/apps/mnesia/mnesia.html
消息数据存储的原理
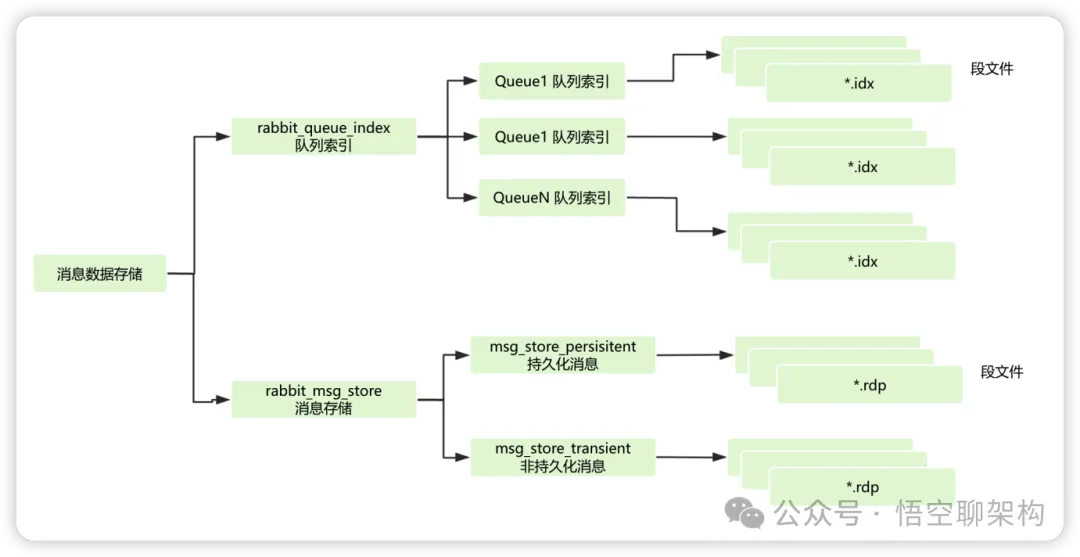
我们知道消息是存储在队列(Queue)中的,底层数据存储的时候,所有 Queue 中的数据的落盘处理都在 RabbitMQ 的“持久层”中完成。持久层是一个逻辑概念,包含了两部分:队列索引(rabbit_queue_index)和消息存储(rabbit_msg_store)。如下图所示:
 img
img
对于消息存储,以Broker节点维度来看,Queue 的消息依次按顺序存储在同一个 rabbit_msg_store 中,这个rabbit_msg_store是一个逻辑概念,底层的存储对应了两个存储单元,分别是 msg_store_persisitent 和 msg_store_transient,分别负责持久化消息和非持久化消息的存储。
msg_store_persisitent 和 msg_store_transient其实是两个文件夹,而具体的消息数据以追加的形式写入到文件夹中的文件中,文件名的后缀是“.rdp”,从0开始累加。当一个文件超过指定的限制后,就会关闭这个文件,再创建一个新的文件以供新的消息写入。这类文件也可称作段文件。
而队列索引(rabbit_queue_index)是负责存储、维护队列中落盘消息的消息,主要包括消息是否ACK、消息的存储位置等等信息。rabbit_queue_index也是以段文件的方式存储数据,每个段文件的后缀是“.idx”。每个 Queue 都会有一个队列索引,所以一个 Broker 节点中会有多个队列索引。
RabbitMQ 提供了过期时间(TTL)功能,用来删除没用的消息。在删除消息时,并不会立即删除消息,只是标记这条消息,直到一个段文件中的消息都被标记为要删除,再将这个文件删除,这个机制就是我们常说的延迟删除。另外还会有合并机制,如果符合合并规则,还会将段文件进行合并。这两种机制在RabbitMQ中协同工作,既保证了消息处理的及时性,又兼顾了存储系统的运行效率,特别适合需要处理海量消息的高并发场景。
RabbitMQ生产消费机制详解
在RabbitMQ架构中,生产者和消费者都是直接与Broker节点交互,无需复杂的客户端寻址机制。客户端连接Broker的方式类似于通过HTTP访问服务端,采用直接连接的方式。值得注意的是:
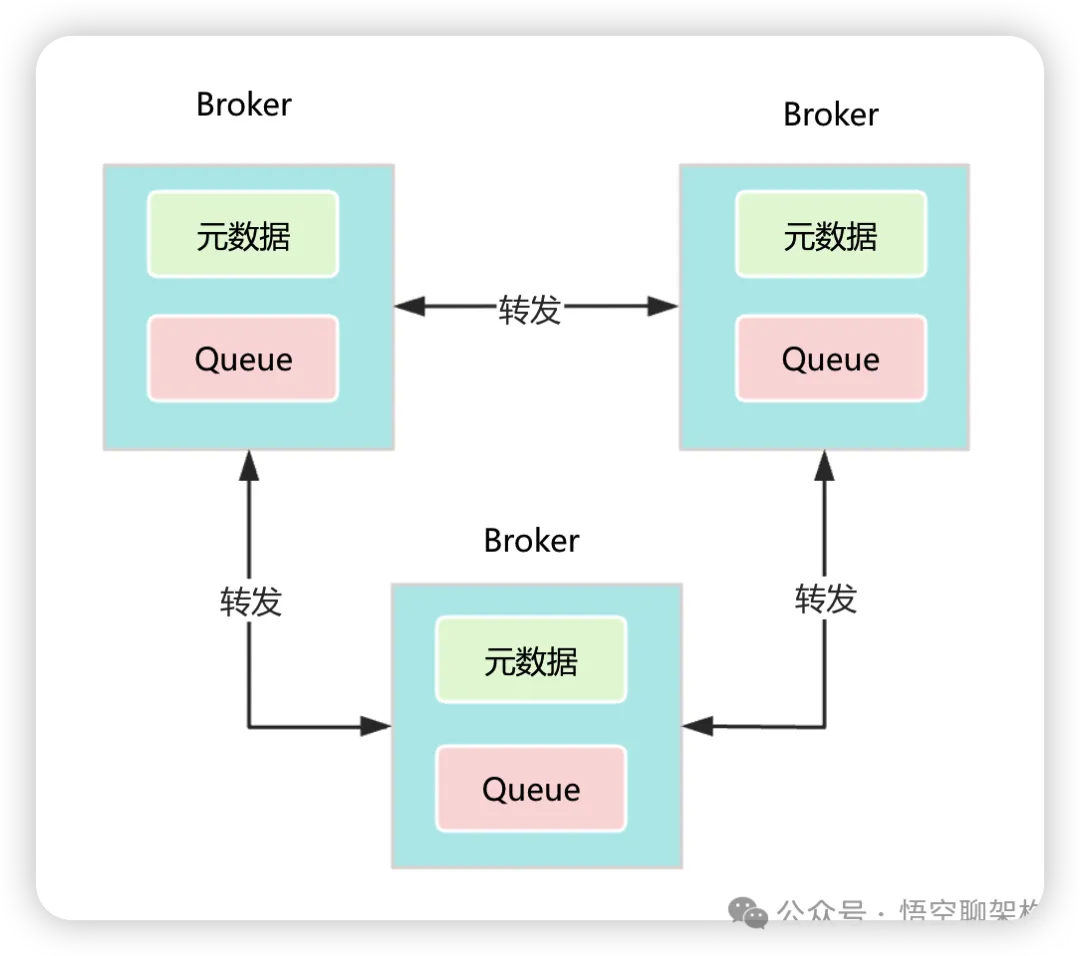
1、Broker节点元数据:每个Broker节点都维护着完整的集群元数据信息,这使得它能够智能地路由请求。当Broker收到请求后,会首先检查本地缓存的元数据,判断目标Queue是否位于当前节点。如果不在此节点,则会自动将请求转发到正确的目标节点。如下图所示:
 img
img
2、生产者路由机制:
(1)生产者直接将数据发送到Broker。
(2)服务端根据预先配置的路由绑定规则将数据分发到不同的Queue。
(3)生产分区分配逻辑完全在服务端完成,由Exchange和Route组件负责。
(4)这种设计移除了客户端的分配策略,简化了客户端实现。
3、消费者模式:
(1)Push模式:Broker主动推送消息到消费者,不需消费者轮询。推送速率受channel.basicQos参数控制,消费者端设有消息缓冲区。
(2)Pull模式:支持消费者主动拉取消息,但每次只能拉取单条消息。
消费模式对比:
| 模式 | 触发方式 | 消息数量控制 | 适用场景 |
|---|---|---|---|
| Push | Broker主动推送 | basicQos限制推送速率 | 高吞吐实时场景 |
| Pull | 消费者主动拉取 | 每次只能拉取单条消息 | 低频精确控制场景 |
4、可靠性保证:
(1) 提供消息确认机制(ACK)
(2) 支持自动ACK和手动ACK两种模式
(3) 消费者直接连接到Queue消费,没有复杂的分组或分区分配机制