Deepseek-V4 VS GPT5 vs Claude vs Gemini 架构级对比
约 943 字大约 3 分钟...
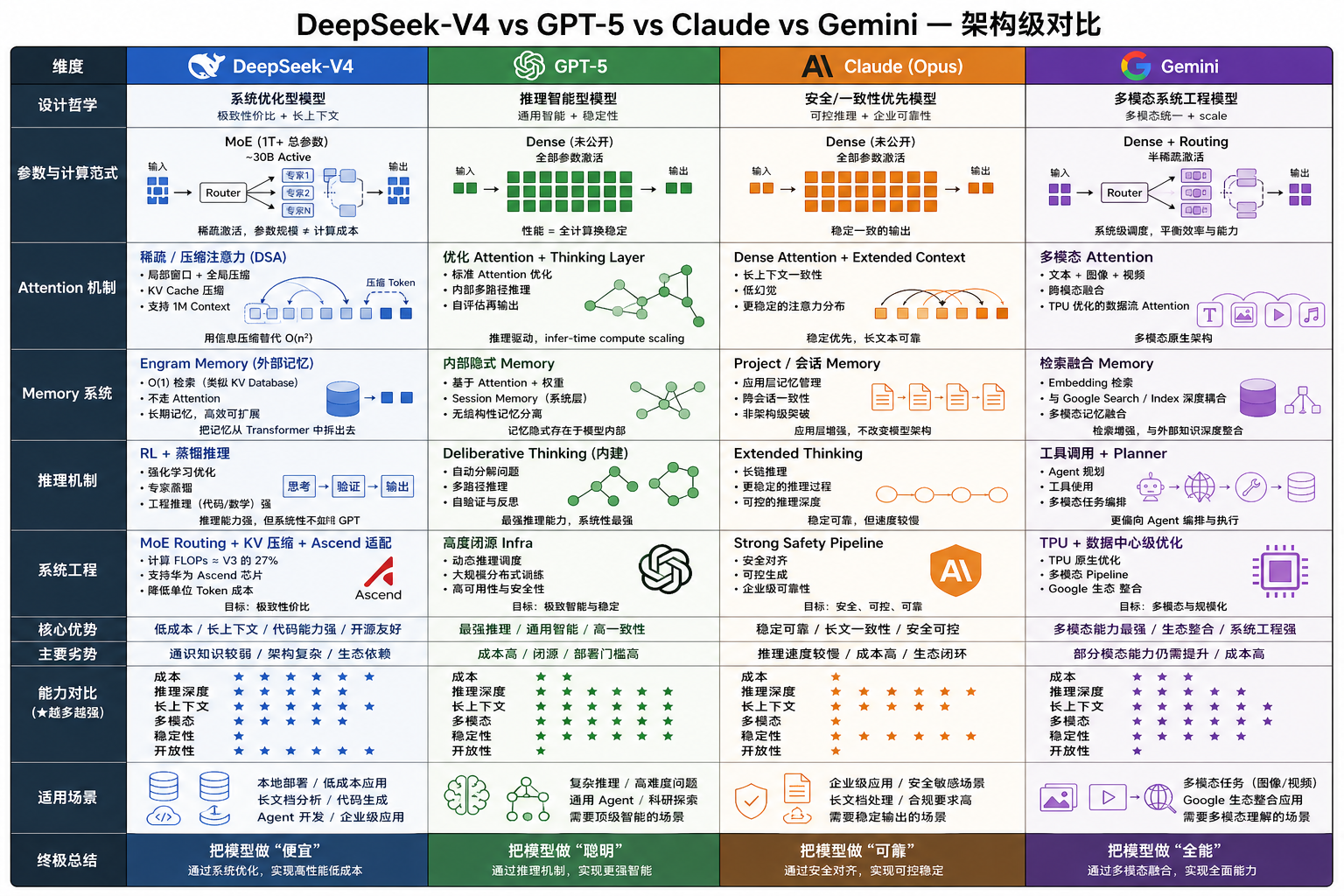
一、总览:四大模型“设计哲学差异”
| 模型 | 核心范式 | 设计目标 |
|---|---|---|
| DeepSeek | MoE + 稀疏注意力 + 外部记忆 | 极致性价比 + 长上下文 |
| GPT-5 | Dense + 推理优先(Thinking) | 通用智能 + 稳定性 |
| Claude (Opus) | Dense + 长上下文 + 安全对齐 | 可控推理 + 企业可靠性 |
| Gemini | Dense + 多模态融合 + TPU系统优化 | 多模态统一 + scale |
👉 一句话:
- DeepSeek = 系统优化型模型
- GPT = 推理智能型模型
- Claude = 安全/一致性优先模型
- Gemini = 多模态系统工程模型
二、核心架构对比(最关键)
1)参数与计算范式
| 模型 | 参数结构 | 激活方式 | 本质差异 |
|---|---|---|---|
| DeepSeek-V4 | MoE(1T+) | ~30B active | 稀疏计算 |
| GPT-5 | Dense(未公开) | 全激活 | 高一致性 |
| Claude | Dense | 全激活 | 稳定输出 |
| Gemini | Dense + routing | 半稀疏 | 系统级调度 |
结论:
- DeepSeek:参数规模 ≠ 计算成本
- GPT / Claude:性能 = 全计算换稳定
👉 MoE本质优势:
用“路由”替代“全部计算”
2)Attention 机制(决定上限)
DeepSeek-V4
- Sparse / 压缩注意力(DSA / latent attention)
- 支持 1M context
- KV cache 压缩
👉 核心:
用“信息压缩”替代 O(n²)
GPT-5
- 标准 Transformer + 优化 attention
- 更重要的是:
👉 “thinking layer(内部推理链)”
- 自动多路径推理
- 自评估再输出
Claude
- Dense attention + extended context
- 更强调:
- 长文本一致性
- 低 hallucination
Gemini
- 多模态 attention(text + image + video)
- TPU 上优化的数据流 attention
总结:
| 模型 | Attention核心 |
|---|---|
| DeepSeek | 压缩 + 稀疏 |
| GPT-5 | 推理驱动 |
| Claude | 稳定长文本 |
| Gemini | 多模态融合 |
3)Memory 系统(关键差异)
DeepSeek-V4(最激进)
- Engram Memory(外部记忆)
- O(1) 检索(类似 KV database)
- 不走 attention
👉 本质:
把“记忆”从 Transformer 中拆出去
GPT-5
- 内部隐式 memory(attention + weights)
- session memory(系统层)
👉 没有结构性 memory 分离
Claude
- “project memory”(会话级)
- 更偏应用层,不是架构突破
Gemini
- 多模态 memory(embedding + retrieval)
- 与 Google search / index 深度耦合
结论:
| 模型 | memory范式 |
|---|---|
| DeepSeek | 外置 memory(类似数据库) |
| GPT-5 | 内部 memory |
| Claude | 应用层 memory |
| Gemini | 检索融合 memory |
4)推理机制(决定“智能”)
GPT-5(最强点)
内建 deliberative thinking
自动:
- 分解问题
- 多路径推理
- 自验证
👉 本质:
inference-time compute scaling
Claude
- extended thinking(长链推理)
- 更稳定但略慢
DeepSeek-V4
RL + 蒸馏推理
更偏:
- 工程推理(code/math)
👉 不如 GPT 系统性强
Gemini
- 工具调用 + planner
- 更偏 agent orchestration
5)系统工程(真正差距来源)
DeepSeek-V4
- MoE routing
- KV 压缩
- 华为 Ascend 适配
👉 目标:
降低单位 token 成本
GPT-5
- 高度闭源 infra
- 动态推理调度
Claude
- 强 safety pipeline
- 可控生成
Gemini
- TPU + 数据中心级优化
- 多模态 pipeline
三、关键能力对比(架构导致结果)
| 能力 | DeepSeek-V4 | GPT-5 | Claude | Gemini |
|---|---|---|---|---|
| 成本 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐ | ⭐⭐ |
| 推理深度 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 长上下文 | ⭐⭐⭐⭐⭐(1M) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 多模态 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| 稳定性 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 开放性 | ⭐⭐⭐⭐⭐ | ⭐ | ⭐ | ⭐ |
四、最本质差异(非常关键)
1)DeepSeek vs GPT(核心对立)
👉 DeepSeek:
用“系统优化”降低成本
👉 GPT:
用“推理机制”提高智能
2)Claude vs GPT
👉 Claude:
更保守、更稳定、更可控
👉 GPT:
更激进、更强推理
3)Gemini vs 其他
👉 Gemini:
唯一真正“多模态原生架构”
五、一个工程师视角的终极总结
如果你是做系统 / Agent / AI infra:
选 DeepSeek-V4
- 需要:
- 低成本
- 本地部署
- 长上下文
- 代码能力
选 GPT-5
- 需要:
- 最强推理
- 复杂 agent
- 高可靠性
选 Claude
- 需要:
- 企业级稳定
- 可控输出
- 长文一致性
选 Gemini
- 需要:
- 多模态(视频/图像)
- Google生态整合
六、一句话“架构哲学对比”
DeepSeek:把模型做“便宜” > GPT:把模型做“聪明” > Claude:把模型做“可靠” > Gemini:把模型做“全能”