开源云原生数据仓库 ByConity ELT 测试
你好,我是悟空。
概述
很高兴能参加 开源云原生数据仓库 ByConity 的测试。接下来我会从以下几个方面来讲述 ByConity 的测试。
- ByConity 简介
- ByConity 原理
- ByConity 测试
官方文档:
https://byconity.github.io/zh-cn/docs/introduction/what-is-byconity
ByConity 简介
ByConity 是新一代的开源的云原生数据仓库,它采用计算-存储分离的架构,在满足数仓用户对资源弹性扩缩容,读写分离,资源隔离,数据强一致性等多种需求的同时,并提供优异的查询、写入性能。ByConity 使用大量成熟 OLAP 技术,例如列存引擎,MPP 执行,智能查询优化,向量化执行,Codegen, indexing,数据压缩等。
ByConity 是由三个单词组成,即:Byte + Convert + Community。其中 By 来自 byte 代表存储数据的基本单位,比喻海量的数据; Con 来自 convert,代表改变和革新; Conity 也来自 community,代表一群人,也就是我们的开源开发者社区。寓意 ByConity 是: 希望汇聚一群尝试打破常规技术的开发者,一起来改变使用数据的方式。
适用场景
- 交互式查询
- 实时数据看板
- 实时数据仓库
- ELT 负载
原理
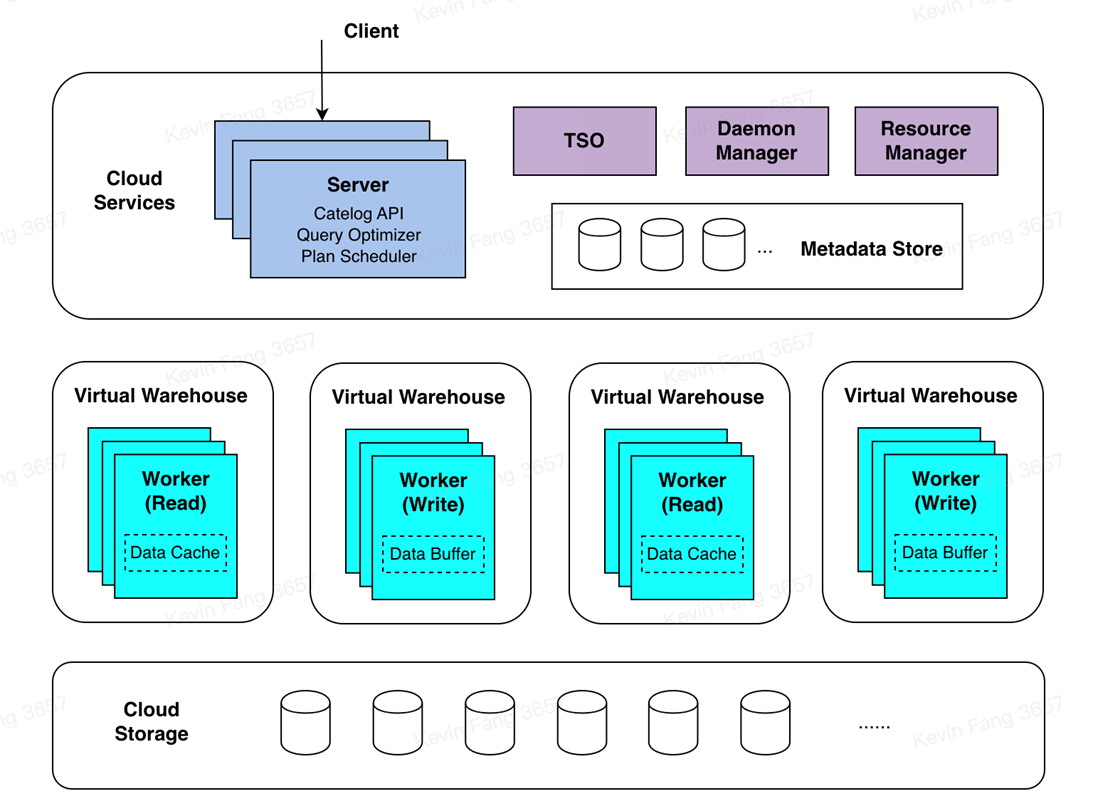
技术架构
ByConity 大体上可以分为 3 层:服务接入层,计算层和存储层。服务接入层响应用户的查询,计算层负责计算数据,存储层存放用户数据。
测试说明
测试环境
| 版本 | 配置 | |
|---|---|---|
| ByConity v1.0.1 | 集群规格 | Worker:4 _ 16core 64G Server:1 _ 16core 64G TSO:1 _ 4core 16G Daemon Manager:1 _ 4core 16G Resource Manager:1 _ 8core 32G 存储:对象存储 TOS FoundationDB:3 _ 4core 16G |
query settings
用户侧可以在 query settings 中通过以下参数使用 ELT 能力。
| 参数名称 | 类型 | 默认值 | 含义 |
|---|---|---|---|
| bsp_mode | Bool | 0 | 打开 bsp 模式,query 会分阶段执行。阶段之间会使用 shuffle 连接。在失败时会进行 task 级别的重试。 |
| distributed_max_parallel_size | UInt64 | 等于 worker 数量 | 当单个查询占用内存较大时,通过调大此参数可以增加算子的并行度,减少单个并行度处理数据的数量,减少单位时间内存使用量。必须在打开 bsp_mode 下才能超出 worker 的数量。建议设置为 worker 个数的倍数。 |
| bsp_max_retry_num | UInt64 | 3 | task 最大的重试次数。 |
| disk_shuffle_files_codec | LZ4/ZSTD/NONE | LZ4 | shuffle 文件采用的编码,能有效减少磁盘占用。 |
来源:https://byconity.github.io/zh-cn/docs/elt/elt-introduction#how-to-use-byconity-elt
测试脚本来源
TPC-DS(Transaction Processing Performance Council Decision Support Benchmark)是一个面向决策支持系统(Decision Support System,简称DSS)的基准测试,该工具是由TPC组织开发,它模拟了多维分析和决策支持场景,并提供了99个查询语句,用于评估数据库系统在复杂的多维分析场景下的性能。每个查询都设计用于模拟复杂的决策支持场景,包括跨多个表的连接、聚合和分组、子查询等高级SQL技术。
测试场景
- 入门测试
- OOM 测试
- 并行度测试
- 非 BSP 模式测试
- 调整最大内存参数测试
ByConity 测试
入门测试
远程连接到服务器
我的本机电脑是 macOs 系统,通过远程工具连接到 ByConity 服务器。服务器地址、账号和密码找小助手提供。
连接数据库
clickhouse client --port 9010
执行查询
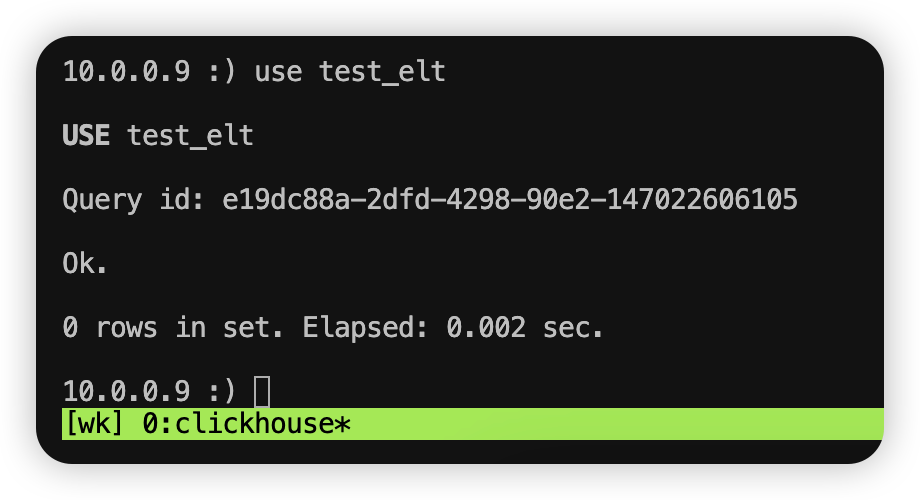
1、使用测试用数据库 test_elt,命令如下
use test_elt
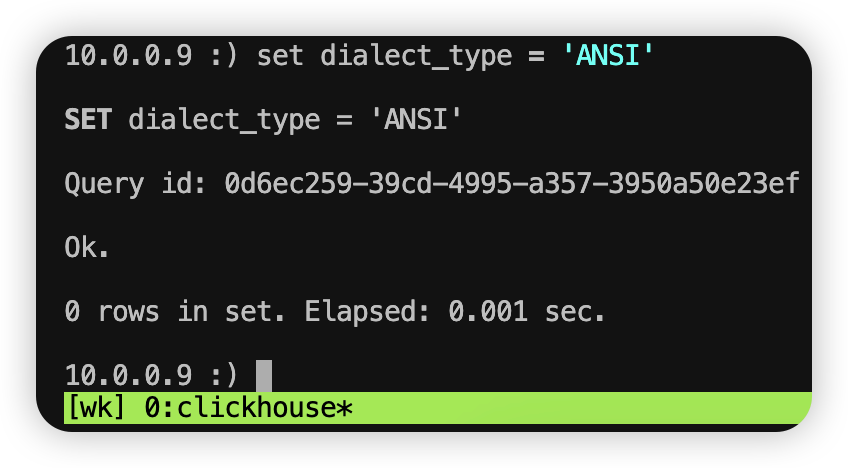
2、由于TPC-DS定义的查询语法为标准 SQL,设置数据库会话的方言类型为 ANSI:
set dialect_type = 'ANSI'
3、选择 TPC-DS 的 99 个查询中某个SQL执行,SQL 列表见 https://github.com/ByConity/byconity-tpcds/tree/main/sql/standard。
4、用第一个 SQL 执行
复制第一个 SQL 语句到命令行
with customer_total_return as
(
select
sr_customer_sk as ctr_customer_sk,
sr_store_sk as ctr_store_sk
,sum(sr_return_amt) as ctr_total_return
from store_returns, date_dim
where sr_returned_date_sk = d_date_sk and d_year = 2000
group by sr_customer_sk,sr_store_sk)
select c_customer_id
from customer_total_return ctr1, store, customer
where ctr1.ctr_total_return > (
select avg(ctr_total_return) *1.2
from customer_total_return ctr2
where ctr1.ctr_store_sk = ctr2.ctr_store_sk
)
and s_store_sk = ctr1.ctr_store_sk
and s_state = 'TN'
and ctr1.ctr_customer_sk = c_customer_sk
order by c_customer_id
limit 100;
复制 SQL 到命令行,如下图所示:
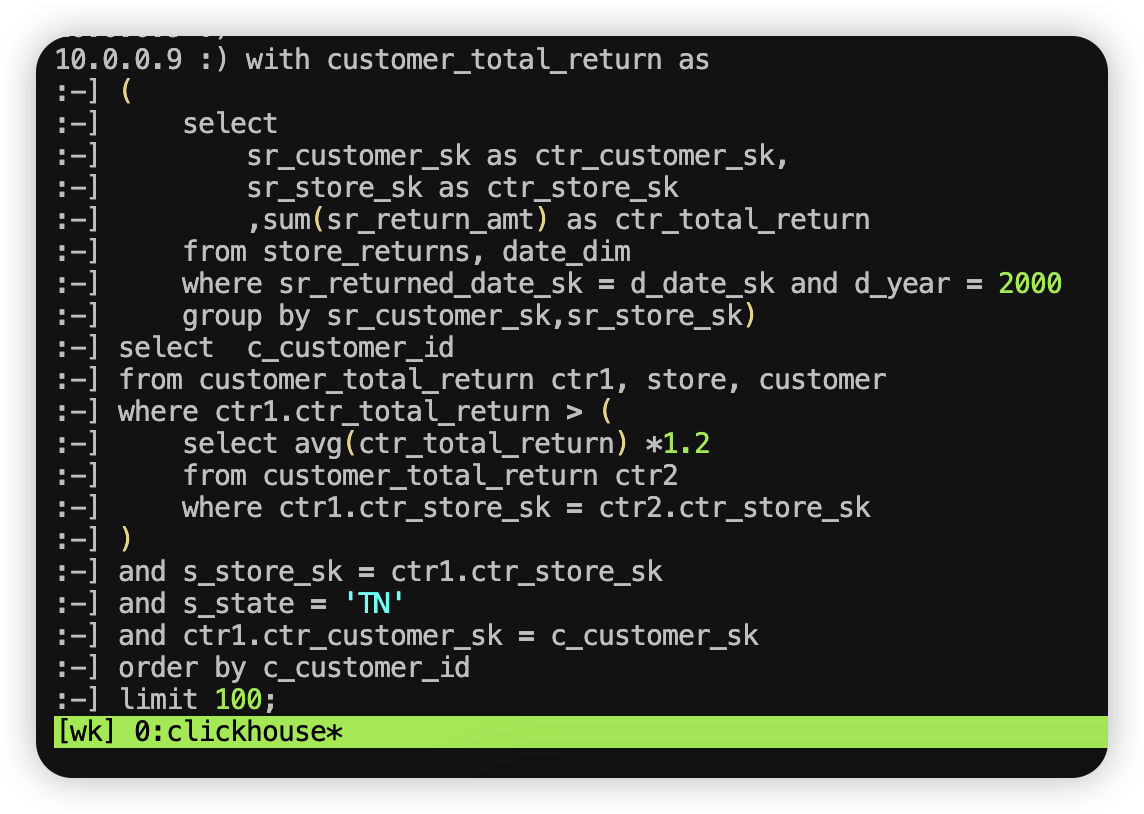
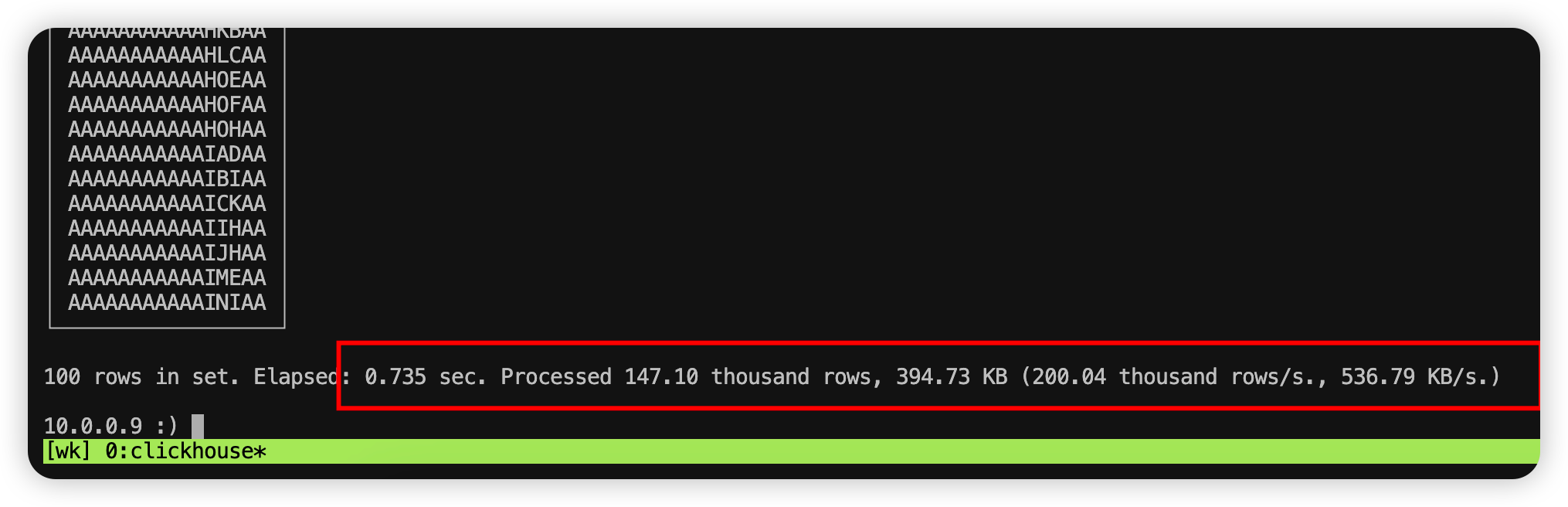
然后回车就会开始执行查询。查询 14W 数据只用了 0.735s,速度还是非常快的。
OOM 测试
我们用第 78 个 SQL 进行测试。
with ws as
(select d_year AS ws_sold_year, ws_item_sk,
ws_bill_customer_sk ws_customer_sk,
sum(ws_quantity) ws_qty,
sum(ws_wholesale_cost) ws_wc,
sum(ws_sales_price) ws_sp
from web_sales
left join web_returns on wr_order_number=ws_order_number and ws_item_sk=wr_item_sk
join date_dim on ws_sold_date_sk = d_date_sk
where wr_order_number is null
group by d_year, ws_item_sk, ws_bill_customer_sk
),
cs as
(select d_year AS cs_sold_year, cs_item_sk,
cs_bill_customer_sk cs_customer_sk,
sum(cs_quantity) cs_qty,
sum(cs_wholesale_cost) cs_wc,
sum(cs_sales_price) cs_sp
from catalog_sales
left join catalog_returns on cr_order_number=cs_order_number and cs_item_sk=cr_item_sk
join date_dim on cs_sold_date_sk = d_date_sk
where cr_order_number is null
group by d_year, cs_item_sk, cs_bill_customer_sk
),
ss as
(select d_year AS ss_sold_year, ss_item_sk,
ss_customer_sk,
sum(ss_quantity) ss_qty,
sum(ss_wholesale_cost) ss_wc,
sum(ss_sales_price) ss_sp
from store_sales
left join store_returns on sr_ticket_number=ss_ticket_number and ss_item_sk=sr_item_sk
join date_dim on ss_sold_date_sk = d_date_sk
where sr_ticket_number is null
group by d_year, ss_item_sk, ss_customer_sk
)
select
ss_sold_year, ss_item_sk, ss_customer_sk,
round(ss_qty/(coalesce(ws_qty,0)+coalesce(cs_qty,0)),2) ratio,
ss_qty store_qty, ss_wc store_wholesale_cost, ss_sp store_sales_price,
coalesce(ws_qty,0)+coalesce(cs_qty,0) other_chan_qty,
coalesce(ws_wc,0)+coalesce(cs_wc,0) other_chan_wholesale_cost,
coalesce(ws_sp,0)+coalesce(cs_sp,0) other_chan_sales_price
from ss
left join ws on (ws_sold_year=ss_sold_year and ws_item_sk=ss_item_sk and ws_customer_sk=ss_customer_sk)
left join cs on (cs_sold_year=ss_sold_year and cs_item_sk=ss_item_sk and cs_customer_sk=ss_customer_sk)
where (coalesce(ws_qty,0)>0 or coalesce(cs_qty, 0)>0) and ss_sold_year=2000
order by
ss_sold_year, ss_item_sk, ss_customer_sk,
ss_qty desc, ss_wc desc, ss_sp desc,
other_chan_qty,
other_chan_wholesale_cost,
other_chan_sales_price,
ratio
LIMIT 100;
然后执行一小段时间后,会提示超过了内存限制,如下图所示:
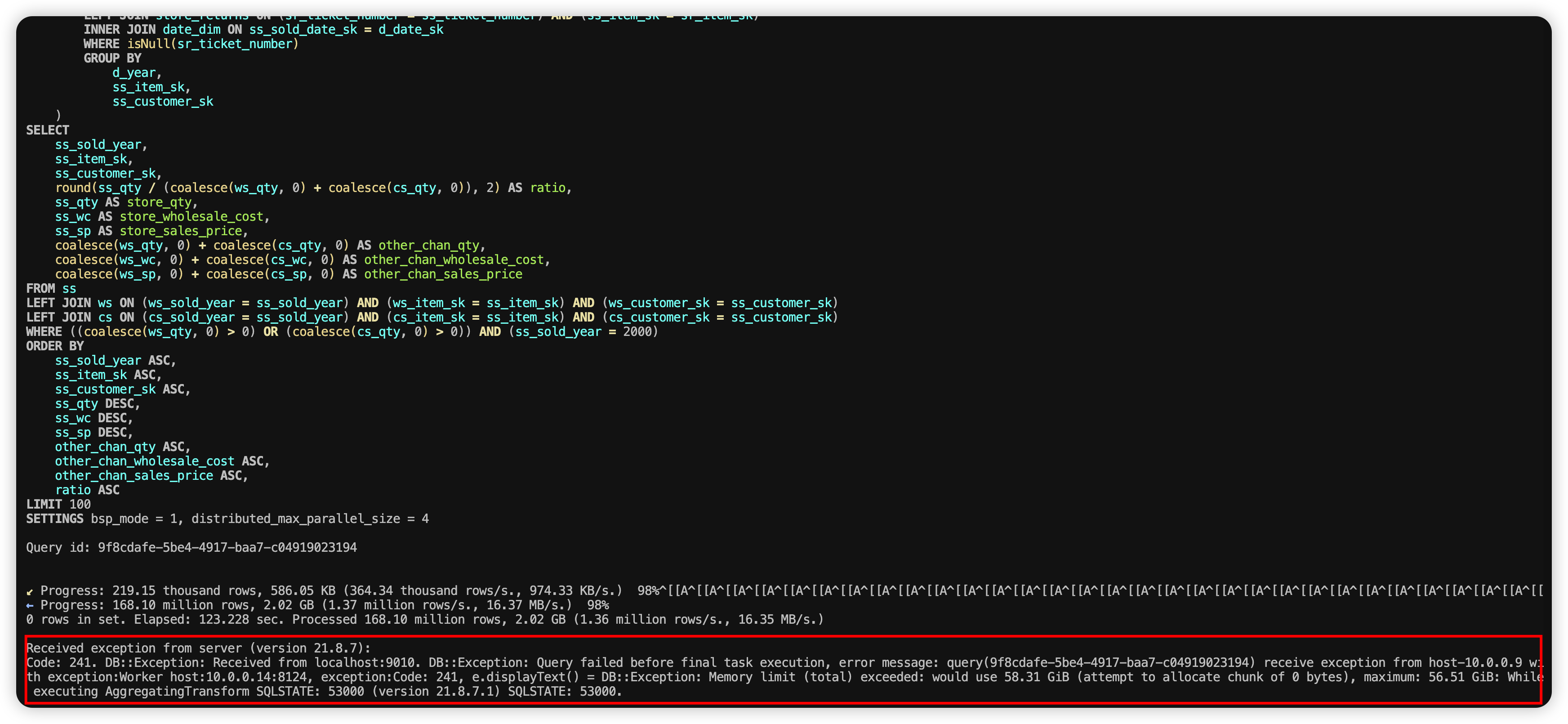
报错信息如下:
Received exception from server (version 21.8.7):
Code: 241. DB::Exception: Received from localhost:9010. DB::Exception: Query failed before final task execution, error message: query(9f8cdafe-5be4-4917-baa7-c04919023194) receive exception from host-10.0.0.9 with exception:Worker host:10.0.0.14:8124, exception:Code: 241, e.displayText() = DB::Exception: Memory limit (total) exceeded: would use 58.31 GiB (attempt to allocate chunk of 0 bytes), maximum: 56.51 GiB: While executing AggregatingTransform SQLSTATE: 53000 (version 21.8.7.1) SQLSTATE: 53000.
这个错误提示的意思是:
- 查询失败:这条 SQL 查询在执行最终任务之前就失败了。
- 内存超限:在执行聚合操作(AggregatingTransform)时,服务器尝试分配更多内存,但超出了允许的最大内存限制。
- 查询需要使用 58.31 GiB 内存,而配置的最大内存限制是 56.51 GiB。
- 因此,系统抛出了一个内存限制异常 (
Memory limit exceeded)。
- 具体位置:查询由主机
10.0.0.9分配到工作节点10.0.0.14:8124执行时出错。 - 错误代码:
241是 ClickHouse 的特定错误代码,通常与内存问题或查询资源使用相关。
原因
- 查询操作涉及到大量的数据,需要进行复杂的计算(例如聚合或排序),导致内存需求超过了服务器的限制。
- 当前配置的最大可用内存不足以支撑该查询。
解决方案
因为之前默认用的参数为
SETTINGS bsp_mode = 1, distributed_max_parallel_size = 4
我们可以调整 distributed_max_parallel_size 参数,表示分布式并行执行的最大数。设置为 4 的其他整数倍(因为 Worker 的数量为4)
当单个查询占用内存较大时,通过调大此参数
distributed_max_parallel_size可以增加算子的并行度,减少单个并行度处理数据的数量,减少单位时间内存使用量。必须在打开 bsp_mode 下才能超出 worker 的数量。建议设置为 worker 个数的倍数。
查询失败后,在失败的 SQL 最后加上以下参数后再次执行可以成功。
SETTINGS
bsp_mode = 1,
distributed_max_parallel_size = 12;
调整并行度测试
调整 distributed_max_parallel_size = 12
接着上面的测试,我们把并行度参数 distributed_max_parallel_size 调整为 12。
修改的 SQL 语句如下:
with ws as
(select d_year AS ws_sold_year, ws_item_sk,
ws_bill_customer_sk ws_customer_sk,
sum(ws_quantity) ws_qty,
sum(ws_wholesale_cost) ws_wc,
sum(ws_sales_price) ws_sp
from web_sales
left join web_returns on wr_order_number=ws_order_number and ws_item_sk=wr_item_sk
join date_dim on ws_sold_date_sk = d_date_sk
where wr_order_number is null
group by d_year, ws_item_sk, ws_bill_customer_sk
),
cs as
(select d_year AS cs_sold_year, cs_item_sk,
cs_bill_customer_sk cs_customer_sk,
sum(cs_quantity) cs_qty,
sum(cs_wholesale_cost) cs_wc,
sum(cs_sales_price) cs_sp
from catalog_sales
left join catalog_returns on cr_order_number=cs_order_number and cs_item_sk=cr_item_sk
join date_dim on cs_sold_date_sk = d_date_sk
where cr_order_number is null
group by d_year, cs_item_sk, cs_bill_customer_sk
),
ss as
(select d_year AS ss_sold_year, ss_item_sk,
ss_customer_sk,
sum(ss_quantity) ss_qty,
sum(ss_wholesale_cost) ss_wc,
sum(ss_sales_price) ss_sp
from store_sales
left join store_returns on sr_ticket_number=ss_ticket_number and ss_item_sk=sr_item_sk
join date_dim on ss_sold_date_sk = d_date_sk
where sr_ticket_number is null
group by d_year, ss_item_sk, ss_customer_sk
)
select
ss_sold_year, ss_item_sk, ss_customer_sk,
round(ss_qty/(coalesce(ws_qty,0)+coalesce(cs_qty,0)),2) ratio,
ss_qty store_qty, ss_wc store_wholesale_cost, ss_sp store_sales_price,
coalesce(ws_qty,0)+coalesce(cs_qty,0) other_chan_qty,
coalesce(ws_wc,0)+coalesce(cs_wc,0) other_chan_wholesale_cost,
coalesce(ws_sp,0)+coalesce(cs_sp,0) other_chan_sales_price
from ss
left join ws on (ws_sold_year=ss_sold_year and ws_item_sk=ss_item_sk and ws_customer_sk=ss_customer_sk)
left join cs on (cs_sold_year=ss_sold_year and cs_item_sk=ss_item_sk and cs_customer_sk=ss_customer_sk)
where (coalesce(ws_qty,0)>0 or coalesce(cs_qty, 0)>0) and ss_sold_year=2000
order by
ss_sold_year, ss_item_sk, ss_customer_sk,
ss_qty desc, ss_wc desc, ss_sp desc,
other_chan_qty,
other_chan_wholesale_cost,
other_chan_sales_price,
ratio
LIMIT 100
SETTINGS
bsp_mode = 0,
distributed_max_parallel_size = 12;
执行成功的结果如下:
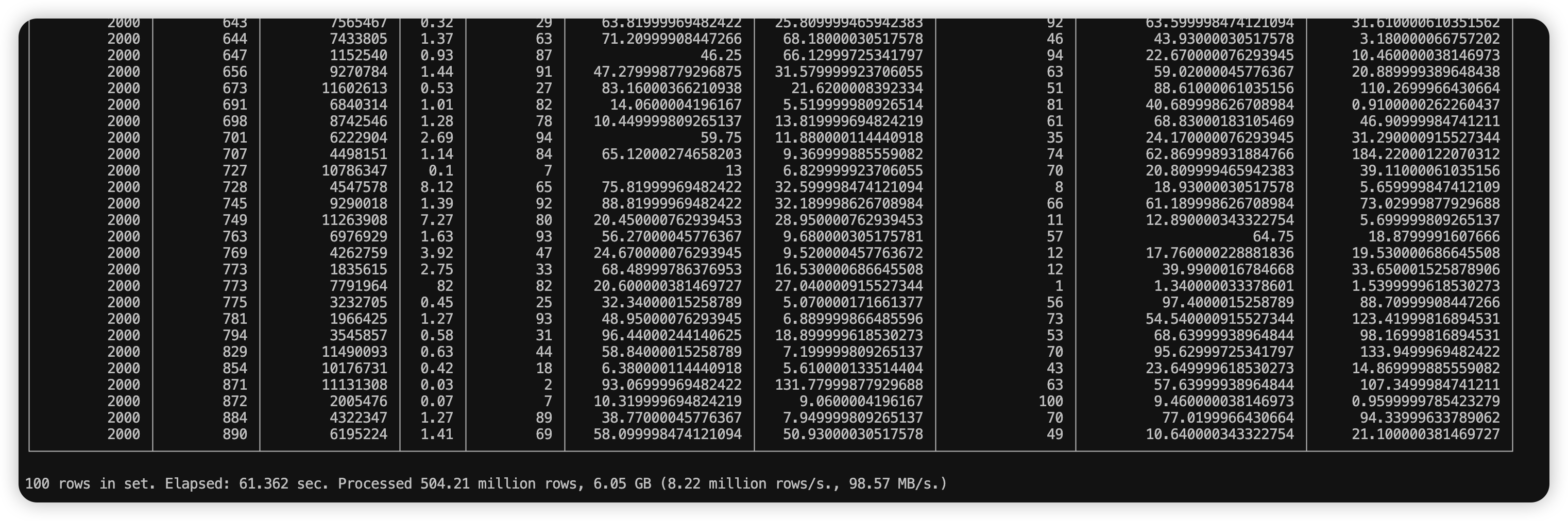
100 rows in set. Elapsed: 61.362 sec. Processed 504.21 million rows, 6.05 GB (8.22 million rows/s., 98.57 MB/s.)
分析 500W 行,且占用 6G 内存的数据,只用了 61s 。
调整 distributed_max_parallel_size = 24
结果如下所示:
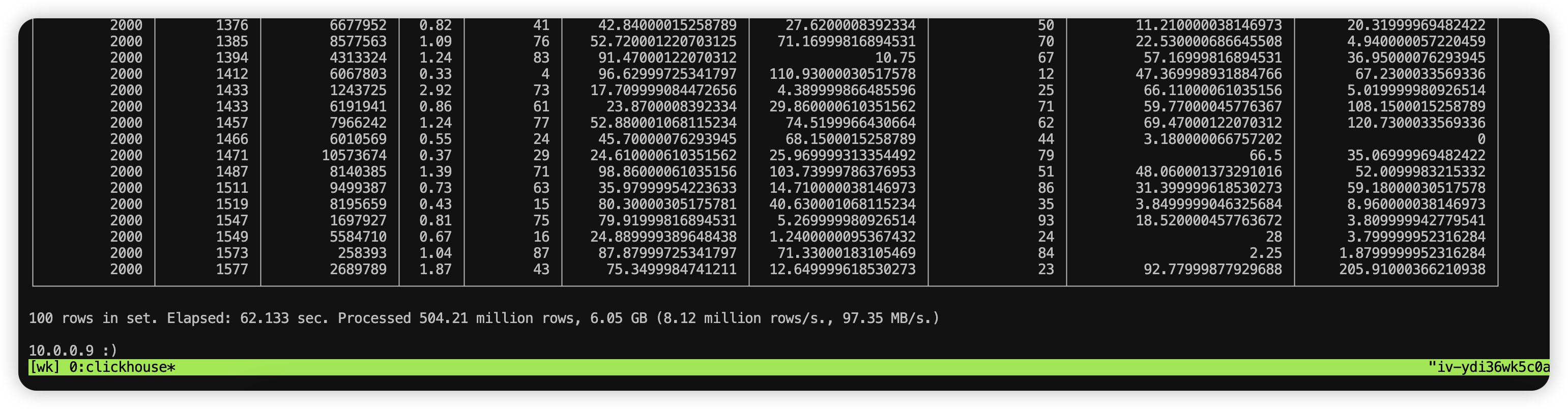
100 rows in set. Elapsed: 62.133 sec. Processed 504.21 million rows, 6.05 GB (8.12 million rows/s., 97.35 MB/s.)
调整 distributed_max_parallel_size = 8
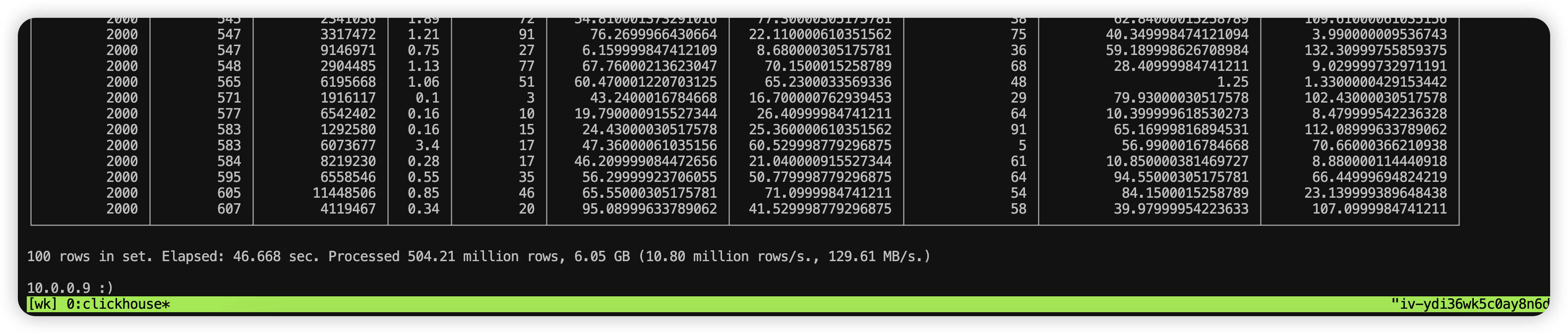
100 rows in set. Elapsed: 46.668 sec. Processed 504.21 million rows, 6.05 GB (10.80 million rows/s., 129.61 MB/s.)

调整 distributed_max_parallel_size = 48

100 rows in set. Elapsed: 119.155 sec. Processed 504.21 million rows, 6.05 GB (4.23 million rows/s., 50.76 MB/s.)
并行度测试对比
| distributed_max_parallel_size | 耗时(秒) | 速度1 (行/s) | 速度2 (MB/s) |
|---|---|---|---|
| 4 | - | - | - |
| 8 | 46.668s | 10.80 million rows/s | 129.61 MB/s |
| 12 | 61.362s | 8.22 million rows/s98.57 MB/s | 98.57 MB/s97.35 MB/s |
| 24 | 62.133s | 8.12 million rows/s | 97.35 MB/s |
| 48 | 119.155s | 4.23 million rows/s | 50.76 MB/s |
经过对比,当 distributed_max_parallel_size = 8 时,查询速度最快,性能最高。12 和 24 查询速度相当,性能相近,48 的时候,查询时间翻倍。
问题:
- 如果查询的数据集是在动态变化的,这个并行度的参数能够自动调整吗?
非 BSP 模式测试
还是用 q78 sql 语句,设置如下参数:
bsp_mode = 0,
distributed_max_parallel_size = 8; 或者 distributed_max_parallel_size = 12;
执行结果如下:
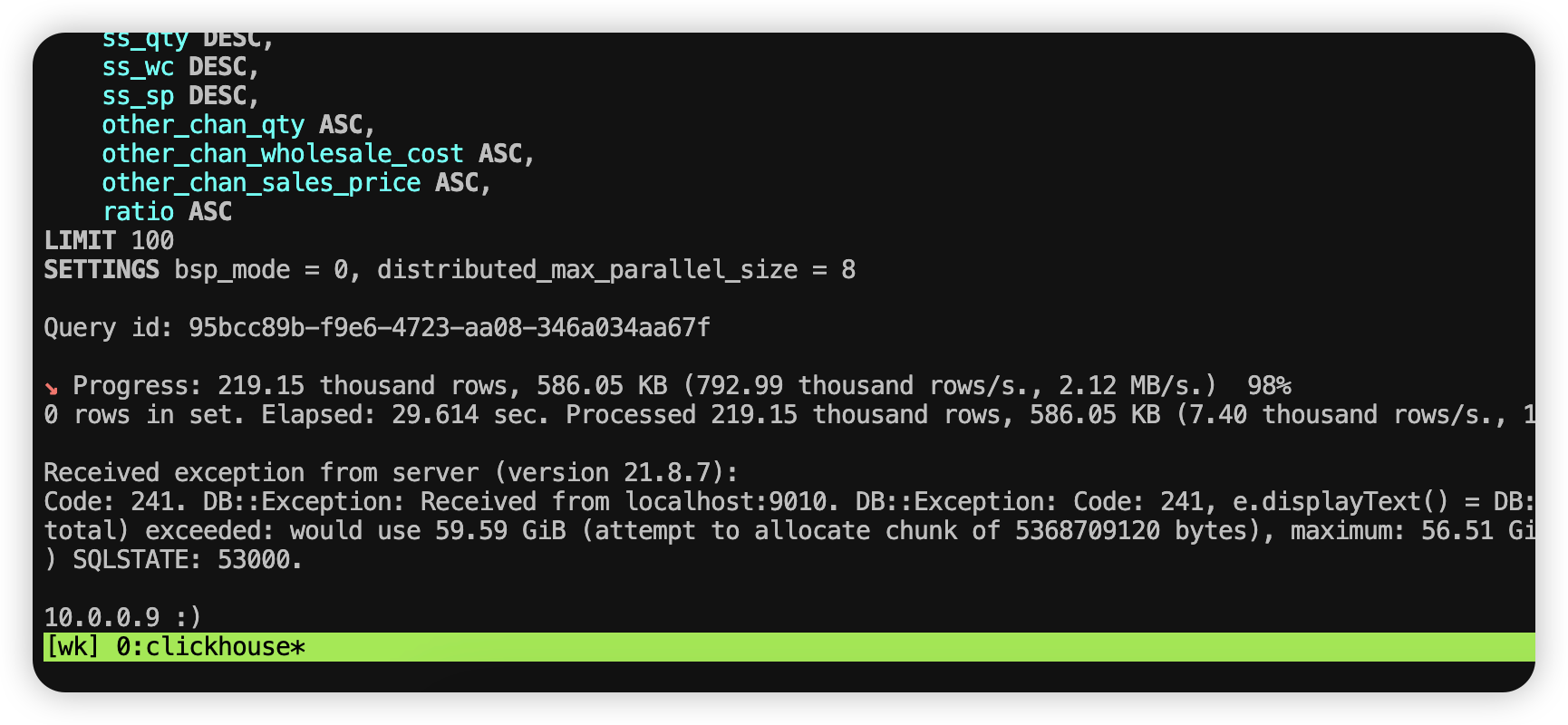
不论是distributed_max_parallel_size = 8 或 distributed_max_parallel_size = 12 都会报内存溢出。
调整最大内存参数测试
执行 q64 SQL 脚本,这个脚本比较复杂,占用的内存较大。
with cs_ui as
(select cs_item_sk
,sum(cs_ext_list_price) as sale,sum(cr_refunded_cash+cr_reversed_charge+cr_store_credit) as refund
from catalog_sales
,catalog_returns
where cs_item_sk = cr_item_sk
and cs_order_number = cr_order_number
group by cs_item_sk
having sum(cs_ext_list_price)>2*sum(cr_refunded_cash+cr_reversed_charge+cr_store_credit)),
cross_sales as
(select i_product_name product_name
,i_item_sk item_sk
,s_store_name store_name
,s_zip store_zip
,ad1.ca_street_number b_street_number
,ad1.ca_street_name b_street_name
,ad1.ca_city b_city
,ad1.ca_zip b_zip
,ad2.ca_street_number c_street_number
,ad2.ca_street_name c_street_name
,ad2.ca_city c_city
,ad2.ca_zip c_zip
,d1.d_year as syear
,d2.d_year as fsyear
,d3.d_year s2year
,count(*) cnt
,sum(ss_wholesale_cost) s1
,sum(ss_list_price) s2
,sum(ss_coupon_amt) s3
FROM store_sales
,store_returns
,cs_ui
,date_dim d1
,date_dim d2
,date_dim d3
,store
,customer
,customer_demographics cd1
,customer_demographics cd2
,promotion
,household_demographics hd1
,household_demographics hd2
,customer_address ad1
,customer_address ad2
,income_band ib1
,income_band ib2
,item
WHERE ss_store_sk = s_store_sk AND
ss_sold_date_sk = d1.d_date_sk AND
ss_customer_sk = c_customer_sk AND
ss_cdemo_sk= cd1.cd_demo_sk AND
ss_hdemo_sk = hd1.hd_demo_sk AND
ss_addr_sk = ad1.ca_address_sk and
ss_item_sk = i_item_sk and
ss_item_sk = sr_item_sk and
ss_ticket_number = sr_ticket_number and
ss_item_sk = cs_ui.cs_item_sk and
c_current_cdemo_sk = cd2.cd_demo_sk AND
c_current_hdemo_sk = hd2.hd_demo_sk AND
c_current_addr_sk = ad2.ca_address_sk and
c_first_sales_date_sk = d2.d_date_sk and
c_first_shipto_date_sk = d3.d_date_sk and
ss_promo_sk = p_promo_sk and
hd1.hd_income_band_sk = ib1.ib_income_band_sk and
hd2.hd_income_band_sk = ib2.ib_income_band_sk and
cd1.cd_marital_status <> cd2.cd_marital_status and
i_color in ('purple','burlywood','indian','spring','floral','medium') and
i_current_price between 64 and 64 + 10 and
i_current_price between 64 + 1 and 64 + 15
group by i_product_name
,i_item_sk
,s_store_name
,s_zip
,ad1.ca_street_number
,ad1.ca_street_name
,ad1.ca_city
,ad1.ca_zip
,ad2.ca_street_number
,ad2.ca_street_name
,ad2.ca_city
,ad2.ca_zip
,d1.d_year
,d2.d_year
,d3.d_year
)
select cs1.product_name
,cs1.store_name
,cs1.store_zip
,cs1.b_street_number
,cs1.b_street_name
,cs1.b_city
,cs1.b_zip
,cs1.c_street_number
,cs1.c_street_name
,cs1.c_city
,cs1.c_zip
,cs1.syear
,cs1.cnt
,cs1.s1 as s11
,cs1.s2 as s21
,cs1.s3 as s31
,cs2.s1 as s12
,cs2.s2 as s22
,cs2.s3 as s32
,cs2.syear
,cs2.cnt
from cross_sales cs1,cross_sales cs2
where cs1.item_sk=cs2.item_sk and
cs1.syear = 1999 and
cs2.syear = 1999 + 1 and
cs2.cnt <= cs1.cnt and
cs1.store_name = cs2.store_name and
cs1.store_zip = cs2.store_zip
order by cs1.product_name
,cs1.store_name
,cs2.cnt
,cs1.s1
,cs2.s1;
执行成功,如下图所示:
问题:如果后续数据集有变化,而这个内存参数已经不适合了,是否能做到自动调整这个参数。
第一次调整 max_memory_usage 参数
然后我们调节 max_memory_usage 参数,
SETTINGS
max_memory_usage=40000000000;
max_memory_usage 的单位为 B,当前约合 37.25 GB
内存不宜限制的过小,可以先用 40000000000 做第一次尝试,如果依然顺利执行,可依次将内存调整为上一次的 70%。
将内存限制为合适的值,引发 oom。随后执行步骤 4,完成查询。
最后选择一个既可以成功执行查询,内存占用又比较小的参数。
第二次调整 max_memory_usage 为 上次的 70%
max_memory_usage = 28000000000,执行成功,如下图所示:
第三次调整 max_memory_usage 为 上次的 70%
max_memory_usage = 19600000000,执行成功,如下图所示:

第四次调整 max_memory_usage 为 上次的 70%
max_memory_usage = 13720000000,执行成功,如下图所示:

第五次调整 max_memory_usage 为 上次的 70%
max_memory_usage = 9640000000,执行成功,如下图所示:

第六次调整 max_memory_usage 为 上次的 70%
max_memory_usage = 6748000000,执行成功,如下图所示:

第七次调整 max_memory_usage 为 上次的 70%
max_memory_usage = 4723600000,执行成功,如下图所示:

第八次调整 max_memory_usage 为 上次的 70%
max_memory_usage = 3306520000,执行成功,如下图所示:

第九次调整 max_memory_usage 为 上次的 70%
max_memory_usage = 2314560000,执行成功,如下图所示:

第十次调整 max_memory_usage 为 上次的 70%
max_memory_usage = 1620190000,执行成功,如下图所示:

第十一次调整 max_memory_usage 为 上次的 70%
当配置 max_memory_usage = 1134140000,执行失败,会引发 OOM。如下图所示:

第十二次调整 max_memory_usage 为 上次的 120%
1134140000 *1.2 = 1360968000,后面几位可以忽略,max_memory_usage = 1360000000,查询还是 OOM 了。

第十三次调整 max_memory_usage 为 上次的 110%
max_memory_usage = 1500000000,查询还是 OOM 了。

第十四次微调 max_memory_usage
max_memory_usage = 1550000000,查询还是 OOM 了。

第十五次微调 max_memory_usage
max_memory_usage = 1550000000,查询还是 OOM 了。

第十六次微调 max_memory_usage
max_memory_usage = 1580000000,查询成功。

小结
先设置了一个较大的内存参数,然后不断地按照 70% 的比例来调整参数进行测试,当出现OOM 时,通过微调参数来满足查询。
总结
通过多种测试,可以看到 ByConity 在 bsp 模式下的表现还是非常不错的,然后通过增加算子的并行度,来减少单个并行度处理数据的数量,从而减少单位时间内存使用量,可以提高查询效率。
ByConity 在 ClickHouse 高性能计算框架的基础上,增加了对 bsp 模式的支持:可以进行 task 级别的容错;更细粒度的调度;在将来支持资源感知的调度。带来的收益有:
- 当 query 运行中遇到错误时,可以自动重试当前的 task,而不是从头进行重试。大大减少重试成本。
- 当 query 需要的内存巨大,甚至大于单机的内存时,可以通过增加并行度来减少单位时间内内存的占用。只需要调大并行度参数即可,理论上是可以无限扩展的。
- (未来)可以根据集群资源使用情况有序调度并发 ETL 任务,从而减少资源的挤占,避免频繁失败。