网络案例排查课-笔记
极客时间课程:https://time.geekbang.com/column/intro/100104301
02 | 抓包分析技术初探:你会用tcpdump和Wireshark吗?
https://time.geekbang.com/column/article/478189
-w 文件名,可以把报文保存到文件;
-c 数量,可以抓取固定数量的报文,这在流量较高时,可以避免一不小心抓取过多报文;
-s 长度,可以只抓取每个报文的一定长度,后面我会介绍相关的使用场景;
-n,不做地址转换(比如 IP 地址转换为主机名,port 80 转换为 http);
-v/-vv/-vvv,可以打印更加详细的报文信息;
-e,可以打印二层信息,特别是 MAC 地址;
-p,关闭混杂模式。所谓混杂模式,也就是嗅探(Sniffing),就是把目的地址不是本机地址的网络报文也抓取下来。
课后习题
第一题:请你用偏移量方法,写一个 tcpdump 抓取 TCP SYN 包的过滤表达式。
答:
来自 @Realm 同学:
匹配SYN+ACK包时(二进制是00010010或是十进制18)
tcpdump -i eth1 'tcp[13] = 18'
匹配SYN或是SYN+ACK的数据时
tcpdump -i eth1 'tcp[13] & 2 = 2'
参考这篇 rfc793 文章: https://datatracker.ietf.org/doc/html/rfc793#section-3.1
从第 13 字节开始,是 TCP 的控制标志位,这些标志位依次为 URG、ACK、PSH、RST、SYN、FIN等。
SYN 为倒数第二位 00000010
ACK 为倒数第五位 00010000
在 TCP 协议中,控制标志位位于 TCP 头部,这些标志位用于控制 TCP 连接的状态和行为。TCP 头部的最小长度是 20 字节,其中前 12 字节包含了源端口、目的端口、序列号和确认号等信息。从第 13 字节开始,是 TCP 的控制标志位,这些标志位包括 SYN、ACK、FIN、RST、PSH、URG 等。
TCP 头部的结构如下:
源端口(Source Port)和目的端口(Destination Port):各占 2 字节,共 4 字节。
序列号(Sequence Number):4 字节。
确认号(Acknowledgment Number):4 字节。
数据偏移(Data Offset):1 字节,指示 TCP 头部的长度。
保留位(Reserved):1 字节,目前必须置为 0。
控制标志位(Control Flags):1 字节,包含 SYN、ACK、FIN、RST、PSH、URG 等标志位。
窗口大小(Window Size):2 字节。
校验和(Checksum):2 字节。
紧急指针(Urgent Pointer):2 字节(如果 URG 标志位为 1 时使用)。
控制标志位的具体含义如下:
SYN(Synchronize Sequence Numbers):同步序列编号,用于建立连接时同步序列编号。在 TCP 三次握手过程中,SYN 标志位被设置为 1,以发起一个新的连接请求
ACK(Acknowledgment):确认标志位,用于确认收到的数据。当 ACK 标志位为 1 时,确认号字段有效,表示对已成功接收的数据段的确认
FIN(Finish):结束标志位,用于释放连接。当 FIN 标志位为 1 时,表示发送方已经没有数据要发送了,希望终止连接
RST(Reset):重置连接。当 RST 标志位为 1 时,表示连接需要被重置或拒绝一个非法的段
PSH(Push):推送标志位,用于提示接收方应尽快将数据推送给应用层
URG(Urgent):紧急标志位,用于指示数据包中有紧急数据,需要优先处理
第二题:如果确定问题是在 IP 层,tcpdump 命令如何写,可以做到既找到 IP 层的问题,又节约抓包文件大小呢?
答:tcpdump -s 34 -w file.pcap
-s 长度,可以只抓取每个报文的一定长度。
帧头 14 字节。
IP头 20 字节。
TCP 头 32 字节。
所有只需要抓取帧头(14字节)和 IP 头(20字节)的数据,后面的 TCP 头和后面的报文就不需要抓取了。
03 | 握手:TCP连接都是用TCP协议沟通的吗?
TCP 三次握手
般来说 TCP 连接是标准的 TCP 三次握手完成的:
1.客户端发送 SYN;
2.服务端收到 SYN 后,回复 SYN+ACK;
3.客户端收到 SYN+ACK 后,回复 ACK。
这里面 SYN 会在两端各发送一次,表示“我准备好了,可以开始连接了”。ACK 也是两端各发送了一次,表示“我知道你准备好了,我们开始通信吧”。
那既然是 4 个报文,为什么是三次发送呢?显然,服务端的 SYN 和 ACK 是合并在一起发送的,就节省了一次发送。这个在英文里叫 Piggybacking,就是背着走,搭顺风车的意思。
如果服务端不想接受这次握手,它会怎么做呢?可能会出现这么几种情况:
1.不搭理这次连接,就当什么都没收到,什么都没发生。这种行为,也可以说是“装聋作哑”。
2.给予回复,明确拒绝。相当于有人伸手过来想握手,你一巴掌拍掉,真的是非常刚了。
第一种情况,因为服务端做了“静默丢包”,也就是虽然收到了 SYN,但是它直接丢弃了,也不给客户端回复任何消息。这也导致了一个问题,就是客户端无法分清楚这个 SYN 到底是下面哪种情况:
1.在网络上丢失了,服务端收不到,自然不会有回复;
2.对端收到了但没回,就是刚才说的“静默丢包”;
3.对端收到了也回了,但这个回包在网络中丢了。
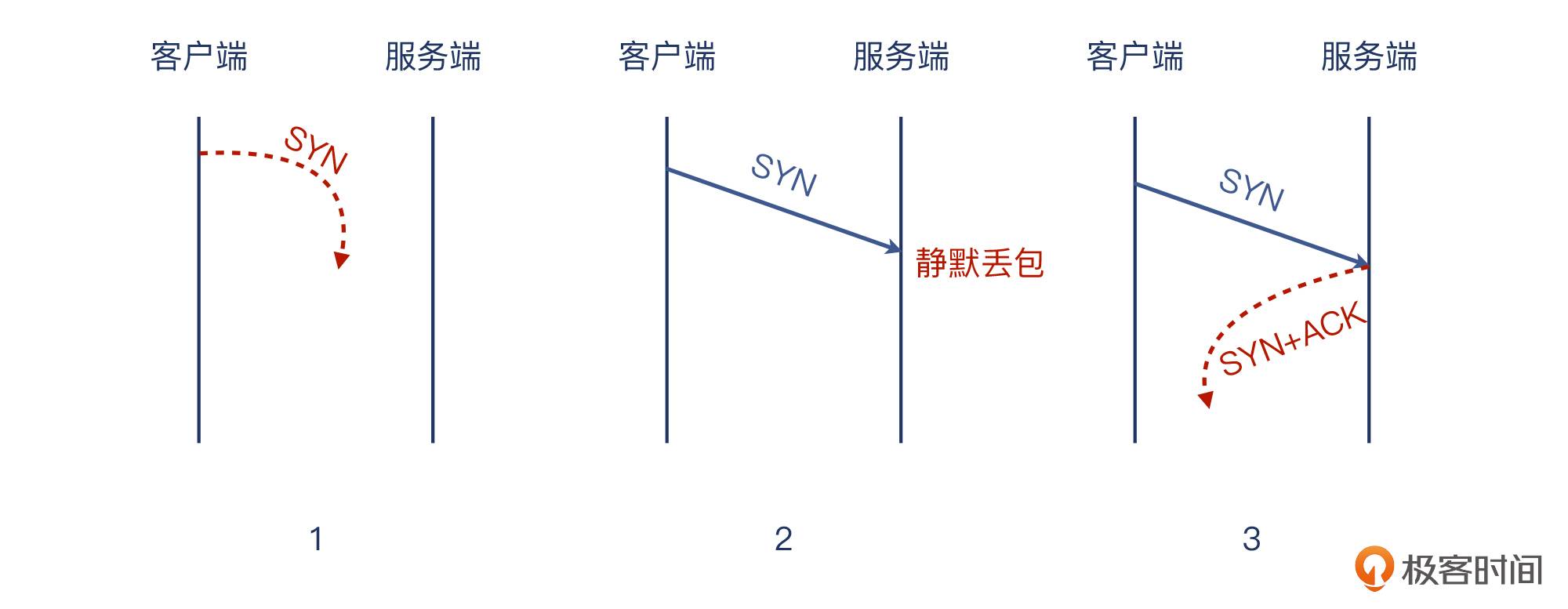
从客户端的角度,对于 SYN 包发出去之后迟迟没有回应的情况,它的策略是做重试,而且不止一次。
试验代码
让 iptables 静默丢弃掉发往自己 80 端口的数据包:
iptables -I INPUT -p tcp --dport 80 -j DROP
在客户端启动 tcpdump 抓包:
sudo tcpdump -i any -w telnet-80.pcap port 80
从客户端发起一次 telnet:
telnet 服务端IP 80
telnet 挂起的原因就在这里:握手请求一直没成功。客户端一共有 7 个 SYN 包发出,或者说,除了第一次 SYN,后续还有 6 次重试。客户端当然也不是“傻子”,这么多次都失败,就放弃了连接尝试,把失败的消息传递给了用户空间程序,然后就是 telnet 退出。
这里有个信息很值得我们关注。第二列是数据包之间的时间间隔,也就是 1 秒,2 秒,4.2 秒,8.2 秒,16.1 秒,33 秒,每个间隔是上一个的两倍左右。到第 6 次重试失败后,客户端就彻底放弃了。显然,这里的翻倍时间,就是“指数退避”(Exponential backoff)原则的体现。这里的时间不是精确的整秒,因为指数退避原则本身就不建议在精确的整秒做重试,最好是有所浮动,这样可以让重试成功的机会变得更大一些。
TCP 握手没响应的话,操作系统会做重试。在 Linux 中,这个设置是由内核参数 net.ipv4.tcp_syn_retries 控制的,默认值为 6,
$ sudo sysctl net.ipv4.tcp_syn_retries
net.ipv4.tcp_syn_retries = 6
以直接 man tcp,查看 tcp 的内核手册的信息。比如下面就是对于 tcp_syn_retries 的解释:
tcp_syn_retries (integer; default: 5; since Linux 2.2) The maximum number of times initial SYNs for an active TCP connection attempt will be retransmitted. This value should not be higher than 255. The default value is 5, which corresponds to approximately 180 seconds.
-A INPUT -p tcp -m tcp --dport 80 -j REJECT --reject-with icmp-port-unreachable
-A INPUT -p tcp -m tcp --dport 80 -j REJECT --reject-with tcp-reset
事实上,无论是收到 TCP RST 还是 ICMP port unreachable 消息,客户端的 connect() 调用都是返回 ECONNREFUSED,这就是 telnet 都报“connection refused”的深层次原因。
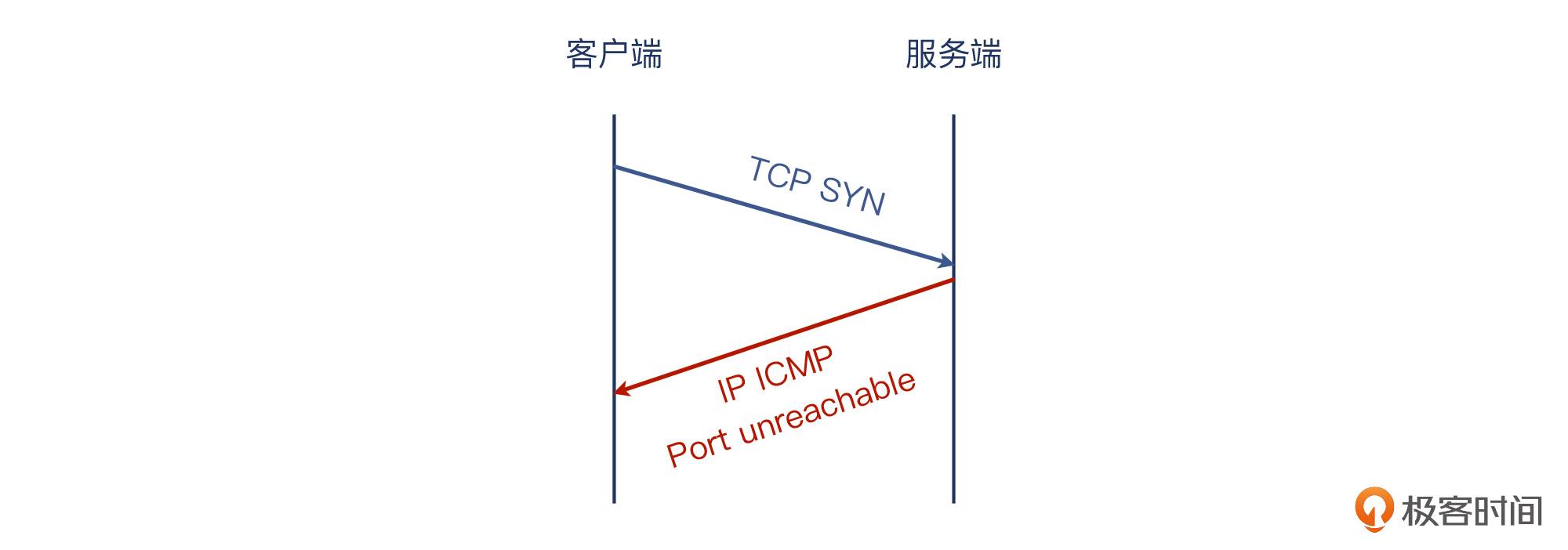
TCP 握手拒绝这个事,竟然可以是 ICMP 报文来达成的。“握手过程用 TCP 协议做沟通”
从此以后,我再也不敢小看任何知识点,同时也领教了 tcpdump 和 Wireshark 在网络分析方面的威力。有了这两个大杀器的帮助,我的网络水平提高很快。
TCP 状态
《UNIX 网络编程:套接字联网 API》
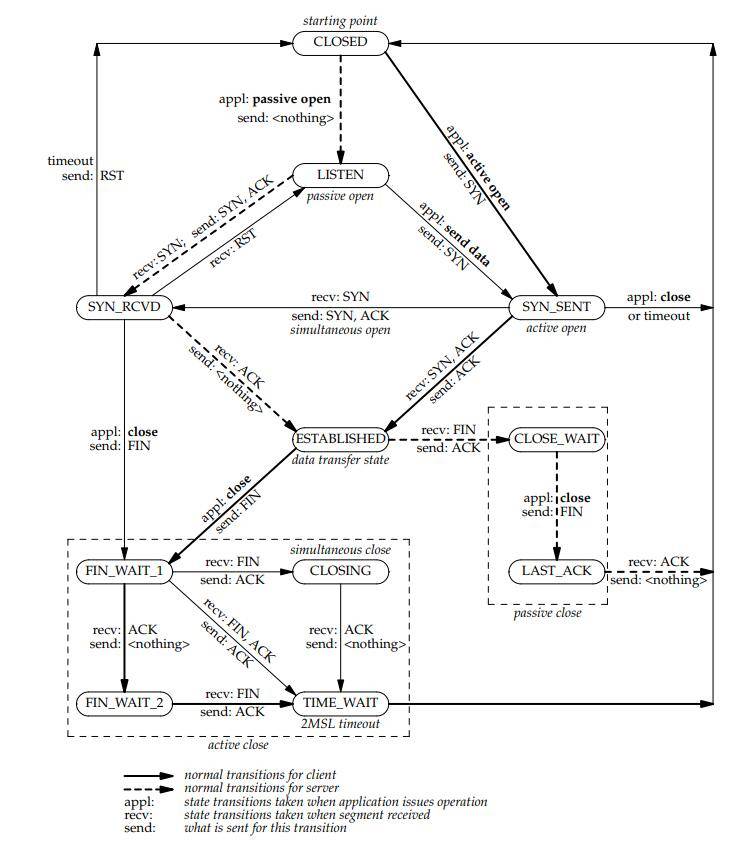
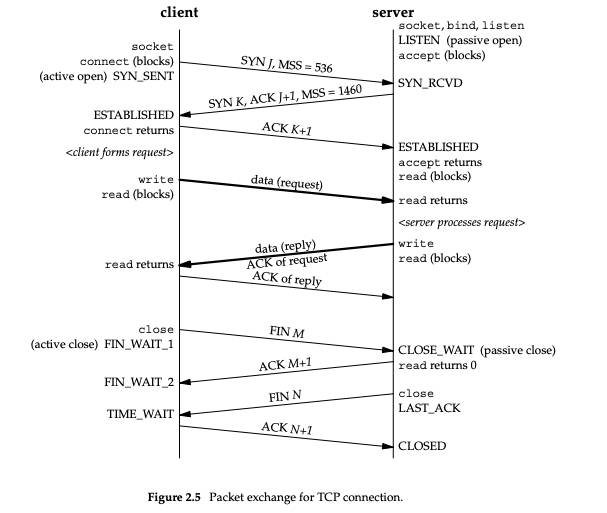
分别沿着左边和右边的垂直线从上往下看,就经历了客户端和服务端的 TCP 生命周期里的各种状态。
windows scale
原先的 Window 字段还是保持不变,在 TCP 扩展部分也就是 TCP Options 里面,增加一个 Window Scale 的字段,它表示原始 Window 值的左移位数,最高可以左移 14 位。
找一个包含了 SYN 报文的抓包文件,选中 SYN 报文,在 Wireshark 窗口中部找到 TCP 的部分,展开 Options 就能看到了:
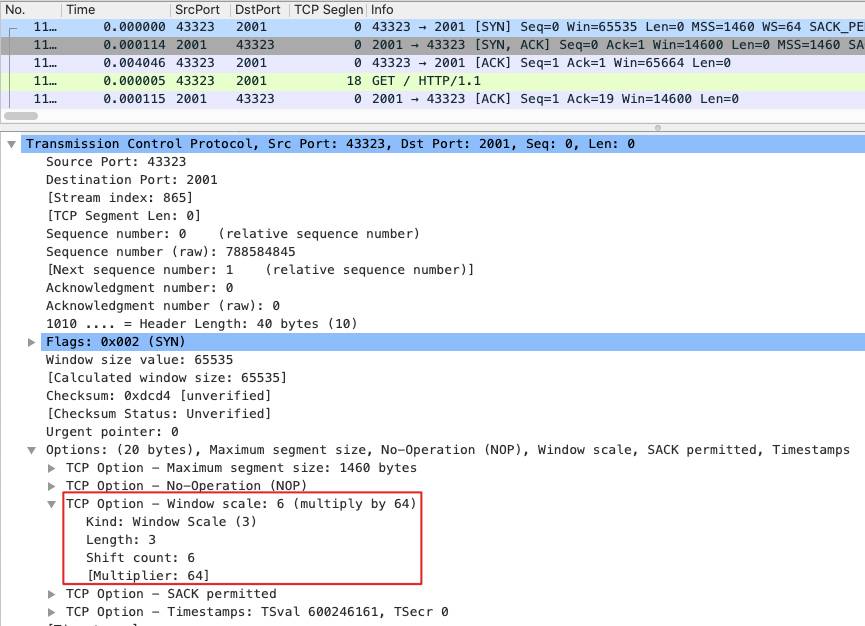
我们逐一理解下。
Kind:这个值是 3,每个 TCP Option 都有自己的编号,3 代表这是 Window Scale 类型。
Length:3 字节,含 Kind、Length(自己)、Shift count。
Shift count:6,也就是我们最为关心的窗口将要被左移的位数,2 的 6 次方就是 64。
小小提醒:SYN 包里的 Window 是不会被 Scale 放大的,只有握手后的报文才会。
小结
作为这个模块的第一课,这次我们围绕 TCP 握手展开了几个有趣的案例,并从中梳理了以下知识点:
客户端发起的连接请求可能因为各种原因没有回复,这时客户端会做重试。一般在 Linux 里,重试次数默认是 6 次,内核参数是 net.ipv4.tcp_syn_retries。重试间隔遵循了指数退避原则。
服务端拒绝 TCP 握手,除了用 TCP RST,另外一种方式是通过 ICMP Destination unreachable(Port unreachable)消息。从客户端应用程序看,这两种回复都属于“对端拒绝”,所以应用表面看不出区别,但我们在抓包的时候要注意,如果单纯抓取服务端口的报文,就会漏过这个 ICMP 消息,可能对排查不利
对于连通性相关的问题,除了用 tcpdump+Wireshark 这个黄金组合,我们还可以在理解 TCP 握手原理的基础上,使用小工具(比如 netstat)来排查。特别是对于 RPC 服务场景,在问题发生时及时执行 netstat -ant,找到 SYN_SENT 状态的连接,这个很可能是突破口。
我们也学习了如何在 Wireshark 中查看 Window Scale。握手包中的 Window Scale 信息十分重要,这会帮助我们知道正确的接收窗口。在分析抓包文件时,要注意是否连接的握手包被抓取到,没有握手包,这个 Window 值一般就不准。可以说,应用都靠连接,连接都靠握手。掌握好了握手,你的 TCP 就算入门了。
就是多读些 TCP 理论,就是多做些抓包分析,就是多处理些案例,更是多走走,多看看。只要有心,你总有机会可以学会,可以成长。
问题
net.ipv4.tcp_synack_retries 是 Linux 内核中的一个 TCP 参数,用于控制服务器在收到客户端的 SYN 请求后重新发送 SYN-ACK 包的次数。这个参数影响 TCP 三次握手的重试行为。
ubuntu 环境
查看参数:
$ sysctl net.ipv4.tcp_synack_retries
net.ipv4.tcp_synack_retries = 5
可以通过以下命令更改 net.ipv4.tcp_synack_retries 的值(需要管理员权限):
$ sudo sysctl -w net.ipv4.tcp_synack_retries=2
或者将其永久写入 /etc/sysctl.conf 文件中:
echo "net.ipv4.tcp_synack_retries=2" | sudo tee -a /etc/sysctl.conf
sudo sysctl -p # 应用更改
04 | 挥手:Nginx日志报connection reset by peer是怎么回事?
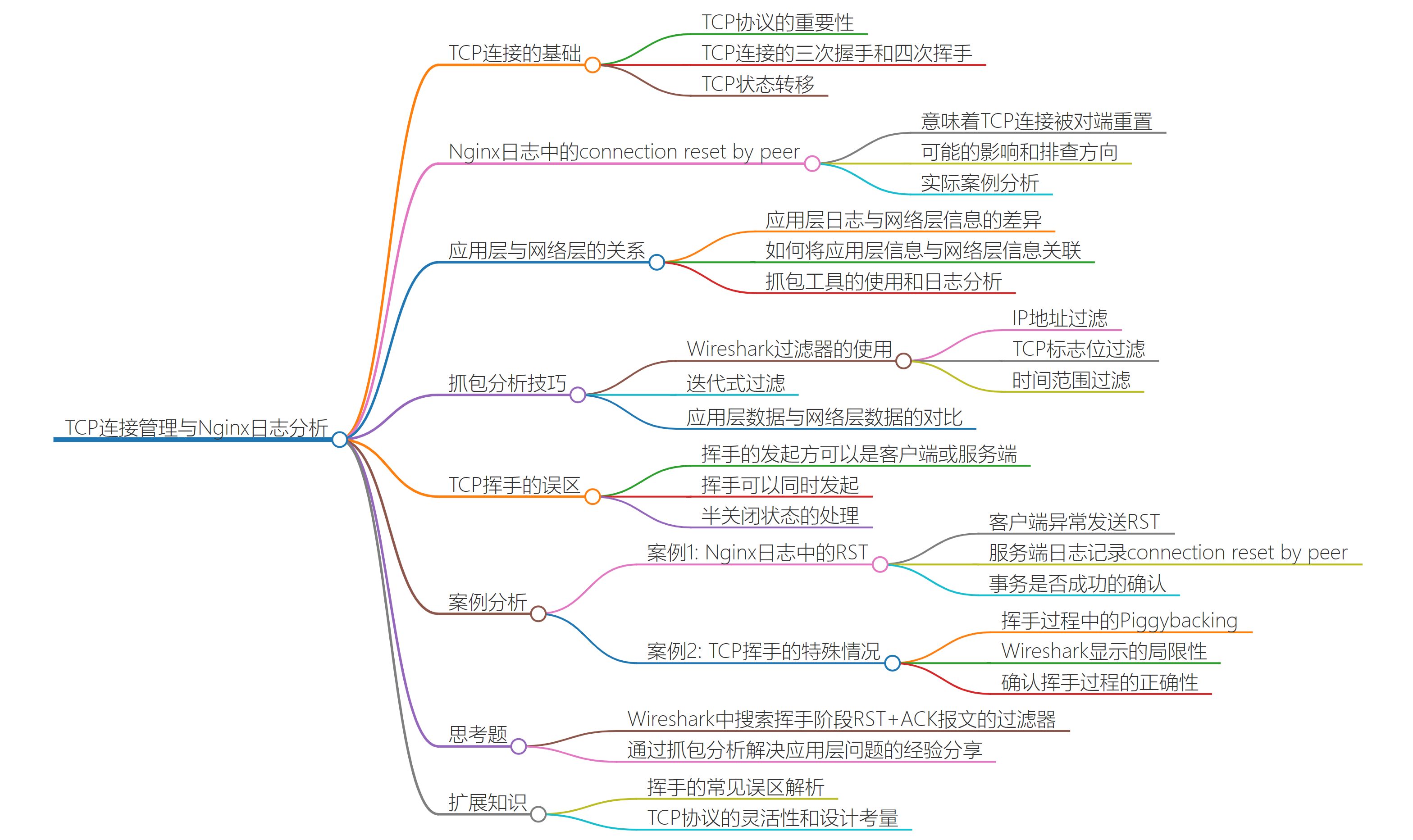
网络排查的第一个要点:把应用层的信息,“翻译”成传输层和网络层的信息。
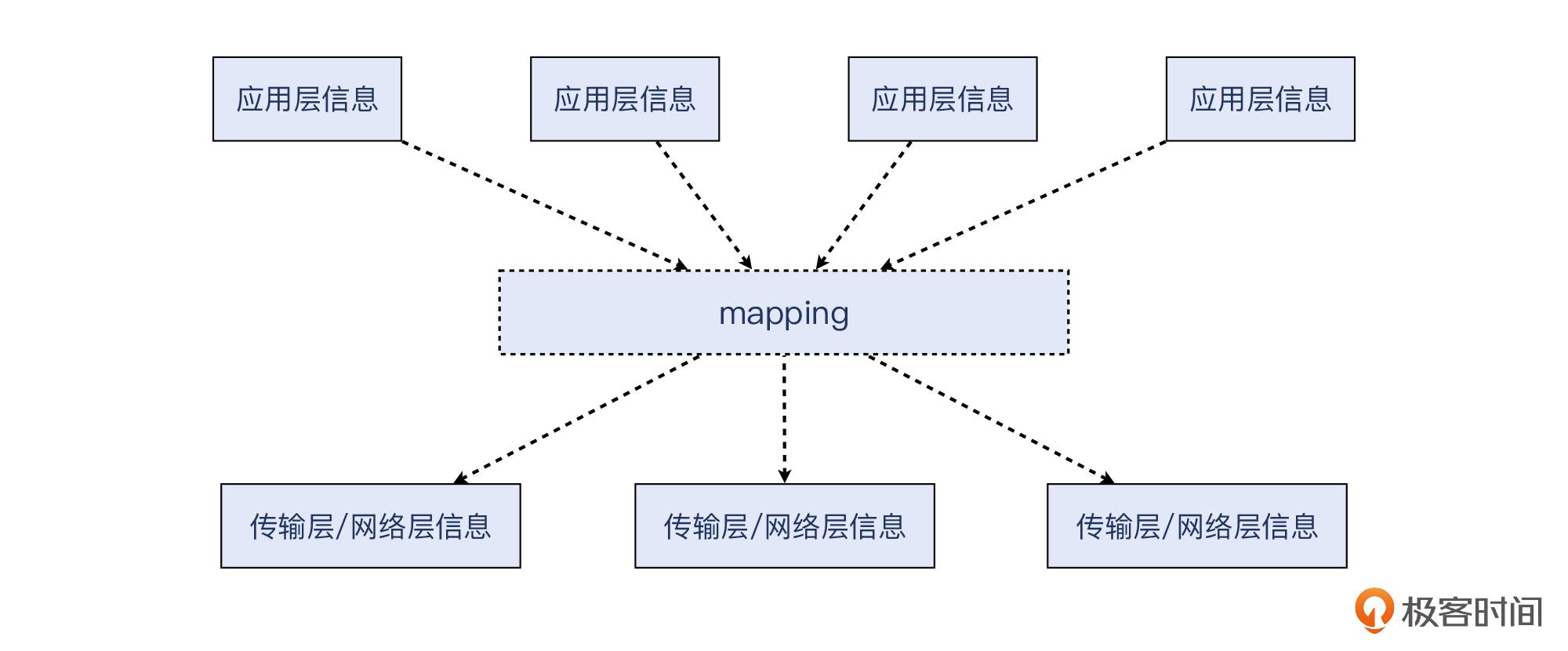
这里我说的“应用层信息”,可能是以下这些:
- 应用层日志,包括成功日志、报错日志,等等;
- 应用层性能数据,比如 RPS(每秒请求数),transaction time(处理时间)等;
- 应用层载荷,比如 HTTP 请求和响应的 header、body 等。
而“传输层 / 网络层信息”,可能是以下种种:
- 传输层:TCP 序列号(Sequence Number)、确认号(Acknowledgement Number)、MSS(Maximum Segment Size)、接收窗口(Receive Window)、塞窗口(Congestion Window)、时延(Latency)、重复确认(DupAck)、选择性确认(Selective Ack)、重传(Retransmission)、丢包(Packet loss)等。
- 网络层:IP 的 TTL、MTU、跳数(hops)、路由表等。
你需要具备把两大鸿沟填平的能力,有了这个能力,你也就有了能把两大类信息(应用信息和网络信息)联通起来的“翻译”的能力。这正是网络排查的核心能力。
案例 1:connection reset by peer?
不过,你也许会问:这种握手阶段的 RST,会不会也跟 Nginx 日志里的 connection reset by peer 有关系呢?要回答这个问题,我们就要先了解应用程序是怎么跟内核的 TCP 协议栈交互的。一般来说,客户端发起连接,依次调用的是这几个系统调用:
socket()
connect()
而服务端监听端口并提供服务,那么要依次调用的就是以下几个系统调用:
socket()
bind()
listen()
accept()
服务端的用户空间程序要使用 TCP 连接来接收请求,首先要获得上面最后一个接口,也就是 accept() 调用的返回。而 accept() 调用能成功返回的前提呢,是正常完成三次握手。
你看,这次客户端在握手中的第三个包不是 ACK,而是 RST(或者 RST+ACK),握手不是失败了吗?那么自然地,这次失败的握手,也不会转化为一次有效的连接了,所以 Nginx 都不知道还存在过这么一次失败的握手。
握手和 HTTP POST 请求和响应都正常,但是客户端在对 HTTP 200 这个响应做了 ACK 后,随即发送了 RST+ACK,而正是这个行为破坏了正常的 TCP 四次挥手。也正是这个 RST,导致服务端 Nginx 的 recv() 调用收到了 ECONNRESET 报错,从而进入了 Nginx 日志,成为一条 connection reset by peer。
frame.time >="Oct 31, 2024 11:48:20" and frame.time <="Oct 31, 2024 11:51:24" and ip.addr eq 10.255.252.31 and tcp.flags.reset eq 1 and !(tcp.seq eq 1 or tcp.ack eq 1)
案例 2:一个 FIN 就完成了 TCP 挥手?
TCP 的挥手是任意一端都可以主动发起的。也就是说,挥手的发起权并不固定给客户端或者服务端。这跟 TCP 握手不同:握手是客户端发起的。
Wireshark 的主界面还有个特点,就是当它的 Information 列展示的是应用层信息时,这个报文的 TCP 层面的控制信息就不显示了。
第一个 FIN 控制报文,并没有像常规的那样单独出现,而是合并(Piggybacking)在 POST 报文里!
这也提醒我们,理解 TCP 知识点的时候需要真正理解,而不是生搬硬套。这一方面需要对协议的仔细研读,另一方面也离不开实际案例的积累和融会贯通,从量变引起质变。
我们自己也要有个态度:大部分时候,当看到 TCP 有什么好像“不合规的行为”,我们最好先反思自己是不是对 TCP 的掌握还不够深入,而不是先去怀疑 TCP,毕竟它也久经考验,它正确的概率比我们高得多,那我们做“自我检讨”,其实是笔划算的买卖,基本“稳赢”。
小结
在这节课里,我们通过回顾案例,把 TCP 挥手的相关技术细节给梳理了一遍。
在案例 1 里面,我们用抓包分析的方法,打通了“应用症状跟网络现象”以及“工具提示与协议理解”这两大鸿沟,你可以再重点关注一下这里面用到的推进技巧:
首先根据应用层的表象信息,抽取出 IP 和 RST 报文这两个过滤条件,启动了报文过滤的工作。
分析第一遍的过滤结果,得到进一步推进的过滤条件(在这个案例里是排除握手阶段的 RST)。
结合日志时间范围,继续缩小范围到 3 个 RST 报文,这个范围足够小,我们可以展开分析,最终找到报错相关的 TCP 流。这种“迭代式”的过滤可以反复好几轮,直到你定位到问题报文。
在这个 TCP 流里,结合对 TCP 协议和 HTTP 的理解,定位到问题所在。
此外,通过这个案例,我也给你介绍了一些 Wireshark 的使用技巧,特别是各种过滤器:
通过 ip.addr eq my_ip 或 ip.src eq my_ip,再或者 ip.dst eq my_ip,可以找到跟 my_ip 相关的报文。
通过 tcp.flags.reset eq 1 可以找到 RST 报文,其他 TCP 标志位,依此类推。
通过 tcp.ack eq my_num 可以找到确认号为 my_num 的报文,对序列号的搜索,同理可用 tcp.seq eq my_num。
一个过滤表达式之前加上“!”或者 not 起到取反的作用,也就是排除掉这些报文。
通过 frame.time >="dec 01, 2015 15:49:48"这种形式的过滤器,我们可以根据时间来过滤报文。
多个过滤条件之间可以用 and 或者 or 来形成复合过滤器。通过把应用日志中的信息(比如 URL 路径等)和 Wireshark 里的 TCP 载荷的信息进行对比,可以帮助我们定位到跟这个日志相关的网络报文。
而在案例 2 里面,我们对“四次挥手”又有了新的认识。通过这个真实案例,我希望你能够了解到:
- 实际上 TCP 挥手可能不是表面上的四次报文,因为并包也就是 Piggybacking 的存在,它可能看起来是三次。
- 在某些特殊情况下,在 Wireshark 里看不到第一个 FIN。这个时候你不要真的把后面那个被 Wireshark 直接展示的 FIN 当作是第一个 FIN。你需要选中挥手阶段附近的报文,在 TCP 详情里面查看是否有
问题
一、对文章内容有点疑问:
1.1、TCP 挥手阶段,我抓包看到的都是
(1)发起端 FIN,ACK
(2) 接收端 ACk
(3) 发起端 FIN,ACK
(4) 接收端ACK
而文中的(1)(4)都是 FIN,不带 ACK。
- 2、最后一张 Stevens 的图,第四次挥手应该是 ACK, SEQ=K+1,ACK+1,这个是我抓包看到的结果。
二、对课后习题有点疑问
2.1 第一题答案为啥是 tcp.flags.ack == 1 and tcp.flags.reset == 1 ?
tcp.flags.ack = 1 很多阶段都会出现,比如三次握手的最后一次握手,怎么判断当 tcp.flags.ack = 1 一定就是挥手阶段。
2.2 遇到的案例,通过抓包分析到客户端发送的两个数据包被服务端处理时,到1024 字节就截断了, 然后其中有个字节被丢弃了,导致程序判断时出现问题。
具体的排查总结在这里:
标题:真·卡了一个1024的 Bug,TCP 的数据包看吐了!
链接地址:https://mp.weixin.qq.com/s/ZfANeLutMkFMvH__apO5MQ
半知半解的排查,很多地方不懂,还有好多知识要啃。
14 | 安全:用Wireshark把DDoS攻击照出原形
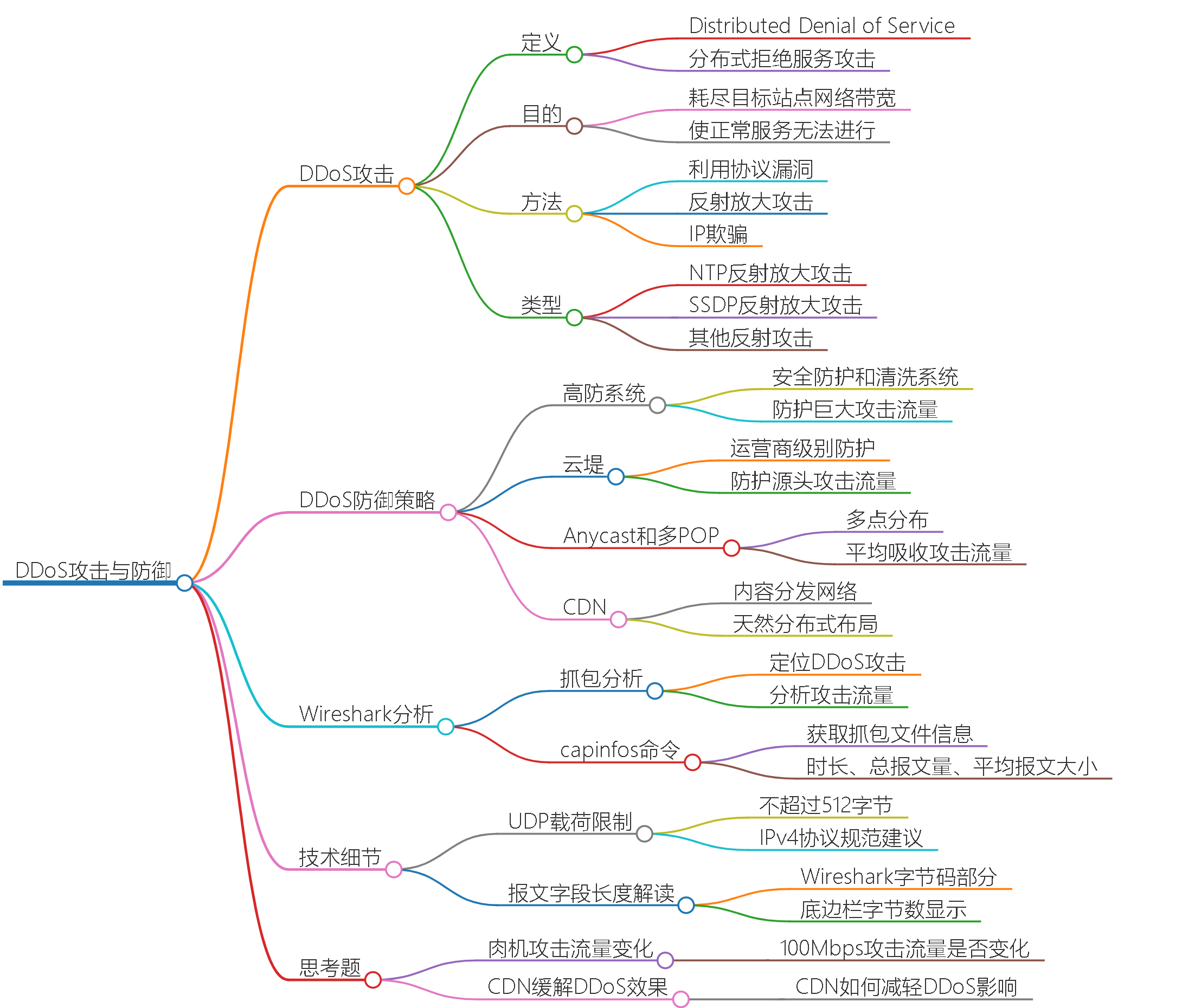
这节课,我们通过 NTP 反射攻击和 SSDP 反射攻击这两个典型的 DDoS 案例的学习,了解了反射放大攻击的特点,它主要利用了以下三点:
IP 协议不对源 IP 进行校验,所以可以伪造源 IP,把它设定为被攻击站点的 IP,这样就可以把响应流量引向被攻击站点。
UDP 协议是无连接的,可以直接进行应用层的一问一答,这就使得 IP 欺骗可以奏效。
某些服务具有“响应报文的大小是请求报文的很多倍”的特点,使攻击行为达到了“四两拨千斤”的攻击效果。
我们也系统性地分析了 DDoS 的核心方法,也就是用“耗尽网络带宽”的方式,让被攻击站点无法正常提供服务。在排查方面,当我们发现服务异常时,在服务端做抓包分析,可以快速定位是否有 DDoS 攻击。也可以直接根据带宽使用图,关注到突发的巨型流量时也可以直接判定是 DDoS 攻击。另外,我们还了解了应对 DDoS 攻击的策略,包括:
- 使用高防产品,可以防护非常巨大的攻击流量。
- 如果对防护效果有更高的需求,可以使用运营商的云堤类的产品。
- 如果自身条件足够,可以部署多 POP 和 anycast,平均吸收攻击流量。
- 也可以上 CDN,让 CDN 天然的分布式布局减轻 DDoS 的影响。
在技术细节方面,你也可以记住这个新的命令 capinfos,用它可以快速获取到抓包文件的整体信息,包括抓包时长、总报文量、平均报文大小等信息。关于如何在 Wireshark 里解读出报文字段的长度,你也要知道至少下面这两种方法:
选中你要解读的报文字段,然后在下面的字节码部分,数一下有底色的字节个数。
还是选中你要解读的报文字段,在底边栏里也有对应的字节数的显示。
最后,你要知道这一点:UDP 载荷最好不要超过 512 字节,这也是 IPv4 协议规范的建议,像 NTP 和 DNS 这些基于 UDP 的协议都实现了这个规范。
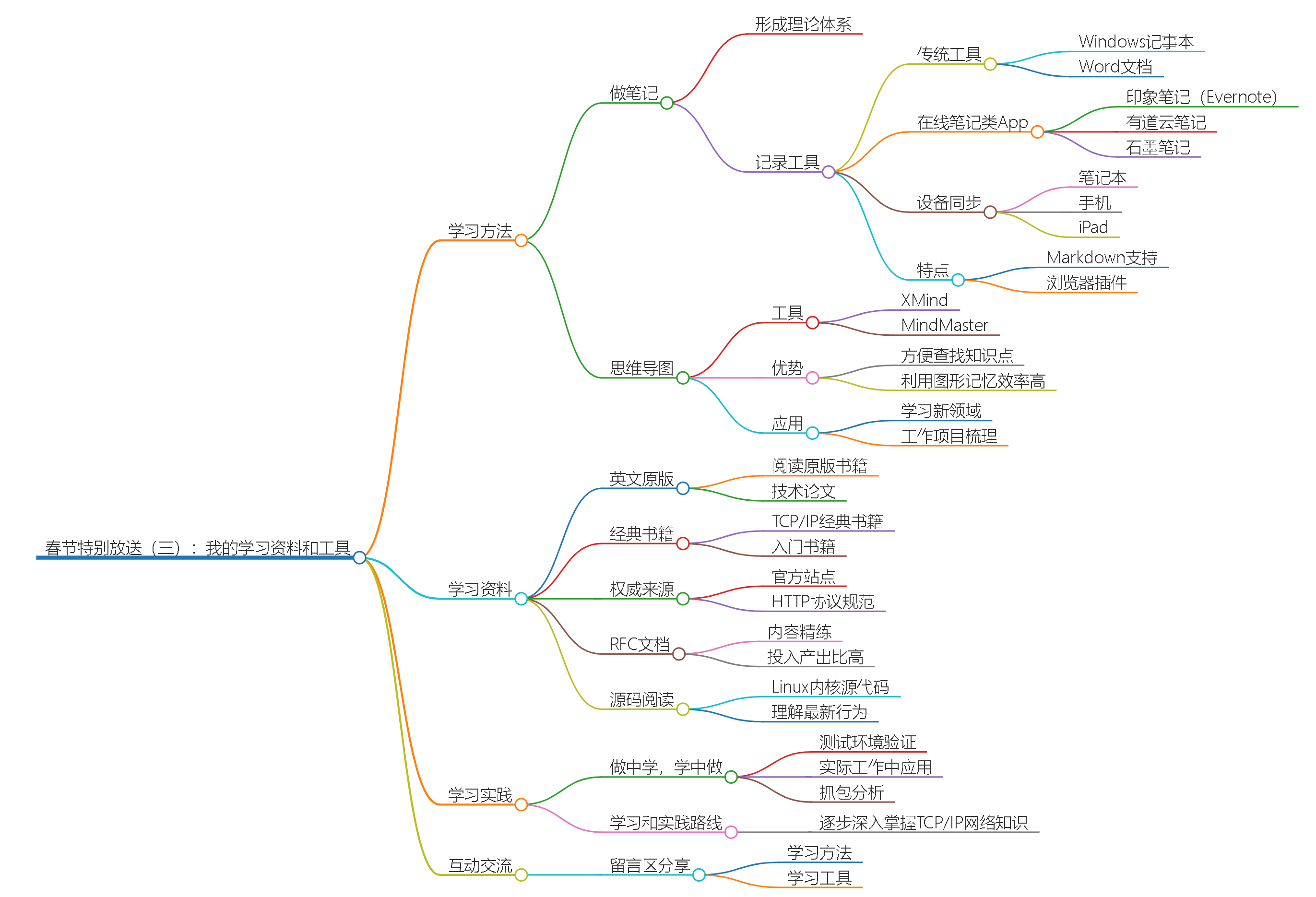
春节特别放送(三)| 我的学习资料和工具
16 | 服务器为什么回复HTTP 400?
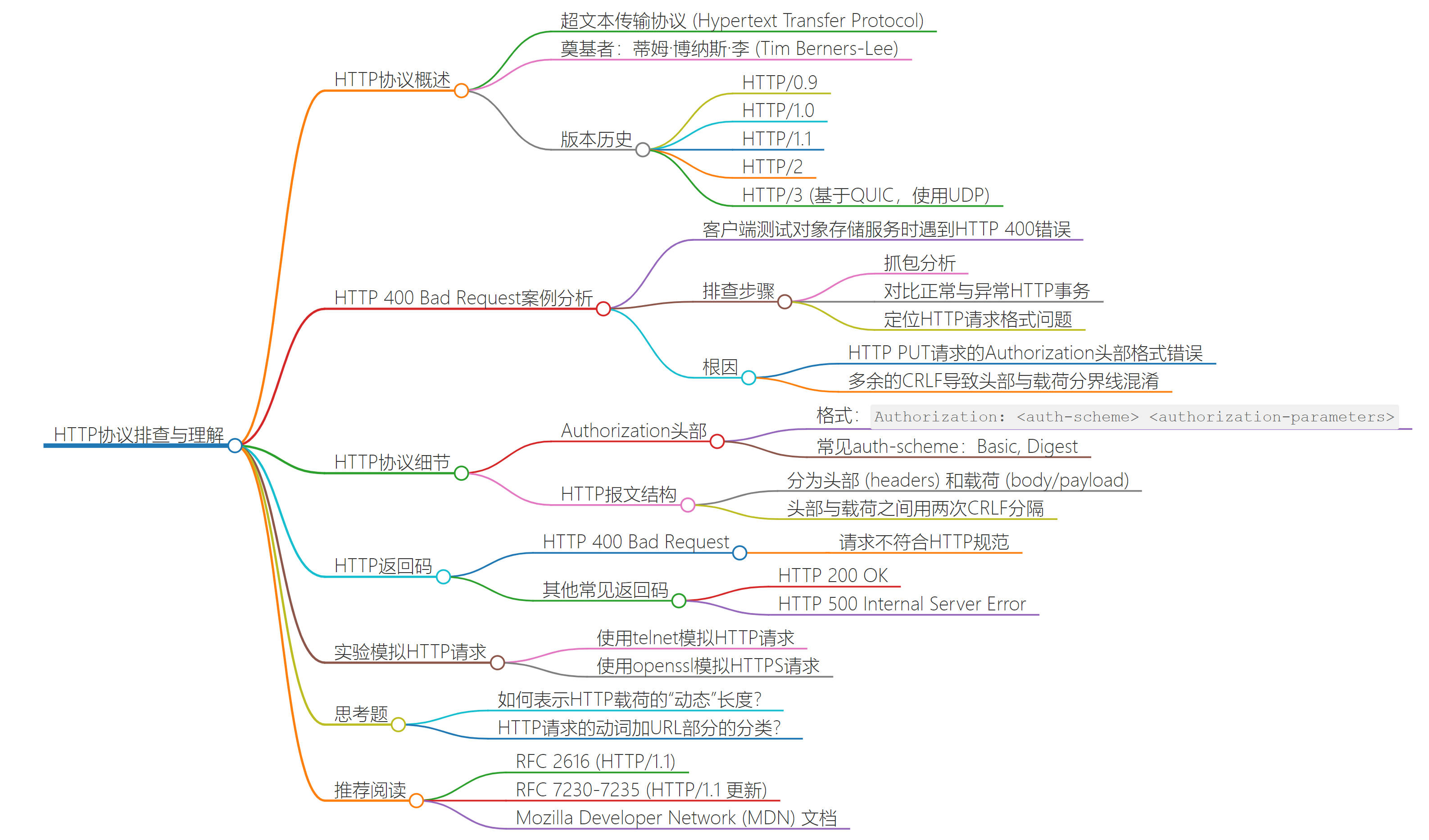
其实,网络协议就是这样,是一种“方言”,互相要用对方听得懂的方式对话。如果语法出现了问题,我们的自然语言就是“不明白你的意思,你说啥”。在 HTTP 这个“方言”里,就是用 HTTP 400 表达了同样的意思。
小结
这节课,我们通过一个服务器回复 HTTP 400 的案例,学习了这种对 HTTP 返回码进行排查的方法。使用这种方法的前提,还是需要你对 HTTP 协议本身有比较深入的掌握,然后结合对 HTTP 语义的理解,分析出根因。而熟悉 HTTP 协议的方法,就是熟读 RFC2616,以及 2014 年 6 月的更新 RFC(7230, 7231, 7232, 7233, 7234, 7235)。具体的方法,我们可以借鉴这样的方式:
我们可以把错误的报文跟成功的报文放一起,进行对比分析。
这样会比较快地发现两者之间的差别,从而更快地定位到根因。
我们也可以通过 telnet 和 openssl,分别模拟复现 HTTP 和 HTTPS 的请求,重放给服务端,观察其是否也返回同样的报错。对比协议规范和报文中抓取到的实际行为,找到不符合规范之处,很可能这就是根因。
同时,我们也回顾了不少 HTTP 协议的知识,包括:HTTP 的各种版本的知识点:
- HTTP/2 和 HTTP/3 的语义跟 HTTP/1.x 是一致的,不同的是 HTTP/2 和 HTTP/3 在传输效率方面,采用了更加先进的方案。
- Authorization 头部的知识点:它的格式为 Authorization: ,如果缺少了某一部分,就可能引发服务端报 HTTP 400 或者 500。
- HTTP 报文的知识点:两次回车(两个 CRLF)是分隔 HTTP 头部和载荷的分隔符。
- HTTP 返回码的知识点:HTTP 400 Bad Request 在语义上表示的是请求不符合 HTTP 规范的情况,各种不合规的请求都可能导致服务端回复 HTTP 400。
最后,我们通过两个小实验,学习了用简单的方式模拟 HTTP 请求的方法。如果服务端是 HTTP,我们用 telnet;如果服务端是 HTTPS,就用 openssl。